Zoom 7.5 comes with the capability to integrate with Artificial Intelligence (AI) providers to analyze files and media in Zoom, store the results from AI, make the results searchable, and display the results in an innovative UI. Data from AI engines can also be used to automatically run tasks based on certain triggers. You can choose to integrate Zoom with Veritone and Amazon AI Providers.
To use AI capabilities with Zoom, choose to use an AI Provider like Veritone or Amazon. You would need their access to their admin consoles to generate access tokens to their services. These tokens will be configured in Zoom.
Prerequisites
Before beginning the setup of AI with your Zoom Server, please ensure these prerequisites are met:
- Basic Zoom setup: your Zoom Server, Preview Server, and Curator Server are installed, configured, and running.
- AI licenses in Zoom: ensure that you have received licenses for the AI Integration and any required engine licenses (such as Veritone AI Engine or Amazon AI Engine) from Evolphin Sales.
- AI Provider admin access: you should have received access to your AI provider’s admin console. This is needed to generate necessary tokens/access keys.
- Designate Hub: designate a server machine inside your network as the Hub. This could also be on the existing Zoom Server or Preview Server machine. This machine should have Java 8 or higher.
- Zoom user account for Hub: plan on having an exclusive Zoom user account for the Hub. One Zoom user account per Hub will be needed.
- SQL for job reporting: either choose a machine to install SQL Server or use an existing SQL Server for storing information related to AI jobs.
- S3 for Veritone: for Veritone AI Provider’s integration in Zoom, ensure that you have an exclusive S3 Bucket to share content with Veritone. Make sure to add expiration rules to clean up the bucket in a fixed number of days. The S3 Bucket Secret Access Key and Access Key ID should have read, write and list permission on the bucket. Keep the Secret Access Key and Access Key ID handy for configuring these in Zoom.
After these prerequisites are met, follow the below steps:
- Check AI licenses on your Zoom Server
- Enable the AI Module in Zoom
- Add Hub Configuration in Zoom
- Set up the Hub Server
- Configure Veritone AI Settings on the Hub Server
- Configure Amazon AI Settings on the Hub Server
- Configure Veritone AI in Zoom
- Configure Amazon AI in Zoom
- Validate Your AI Setup
Check AI licenses in Zoom
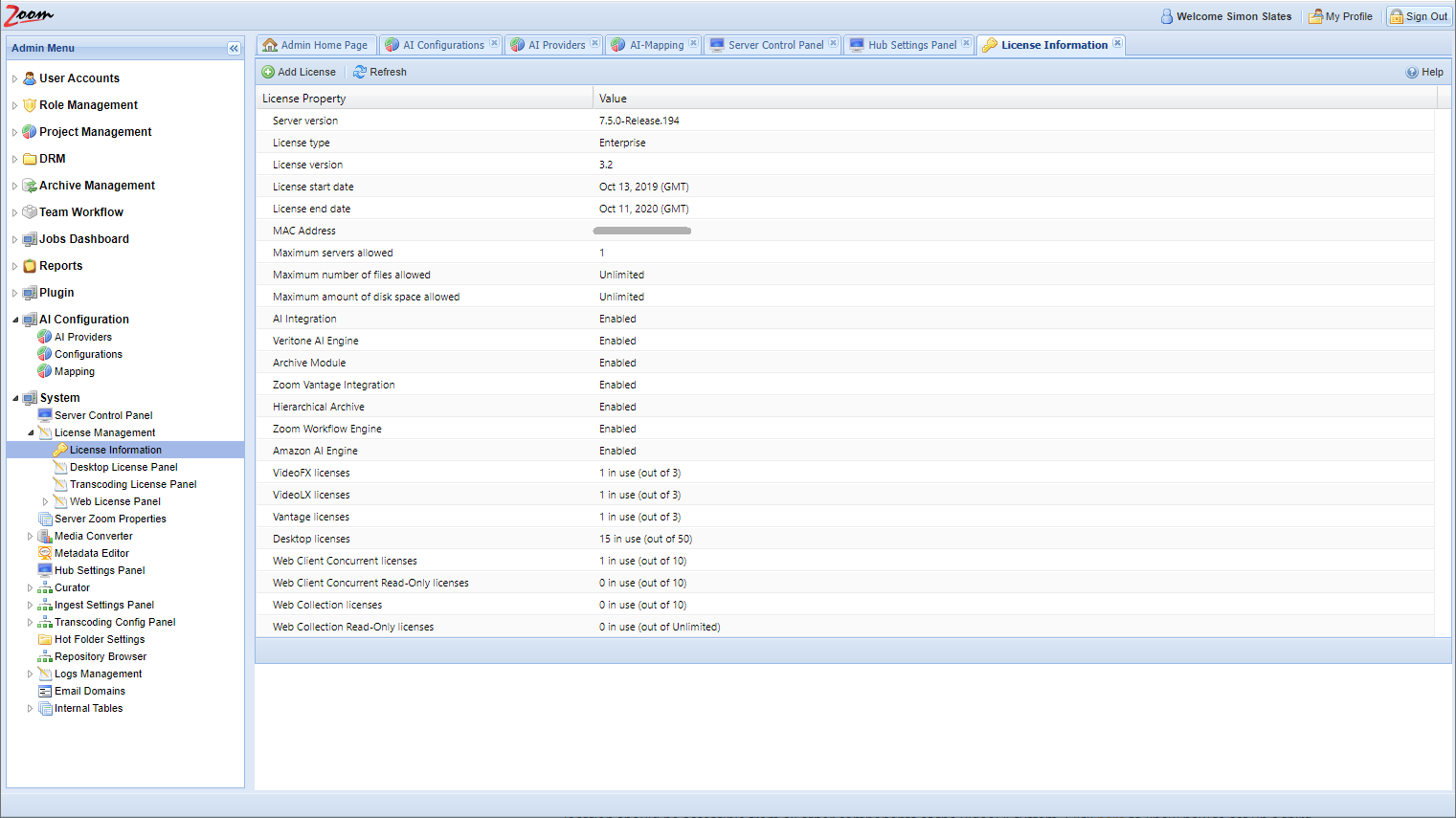
Check if you have all licenses needed for AI and at least one AI Provider. These licenses are shown in the Web Management Console.
In the Web Management Console, open the License Management node under the System node in the Admin Menu sidebar. Open License Information page. Check that AI Integration is Enabled. If it is not enabled, then check with Evolphin Support.
Also, check that your required AI Engine is enabled. Zoom supports Veritone AI Engine and Amazon AI Engine currently. If the AI Engines are not enabled then check with Evolphin Support to get these. You would need at least one AI Engine license to set up AI in Zoom.
Enable the AI Module in Zoom
We need to enable AI in Zoom before beginning to configure it. Follow these steps to enable AI for the first time or to update the AI Settings later:
- Open the Web Management Console for your Zoom Server. Example: https://zoom-server:9443
- Log in using your admin credentials.
- In the Admin Menu sidebar, click Server Control Panel under the System node.
- Click AI Settings on the Server Control Panel page.
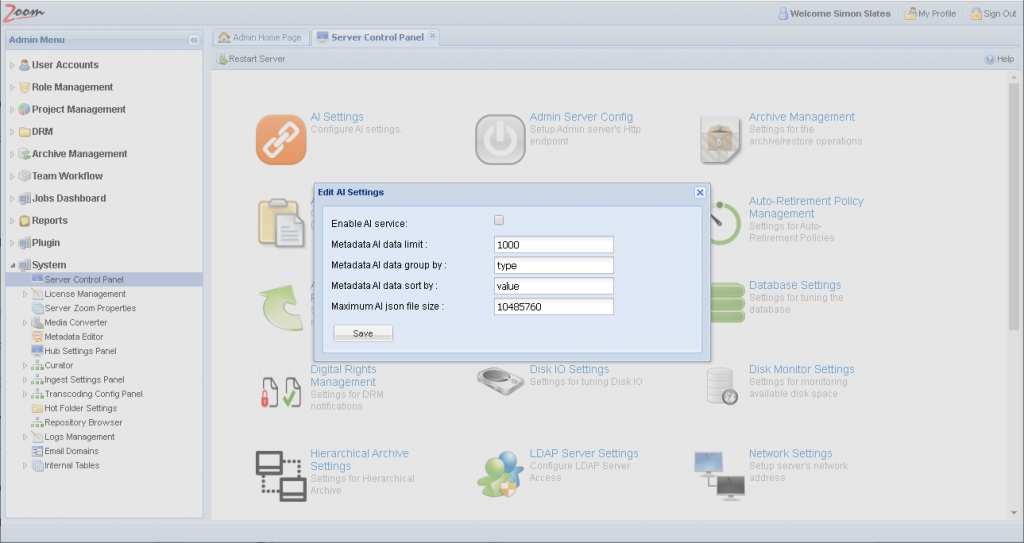
- When enabling for the first time, click Enable AI service and then click Save.
- Reload the browser page. A new node called AI Configuration is added to the Admin Menu sidebar.
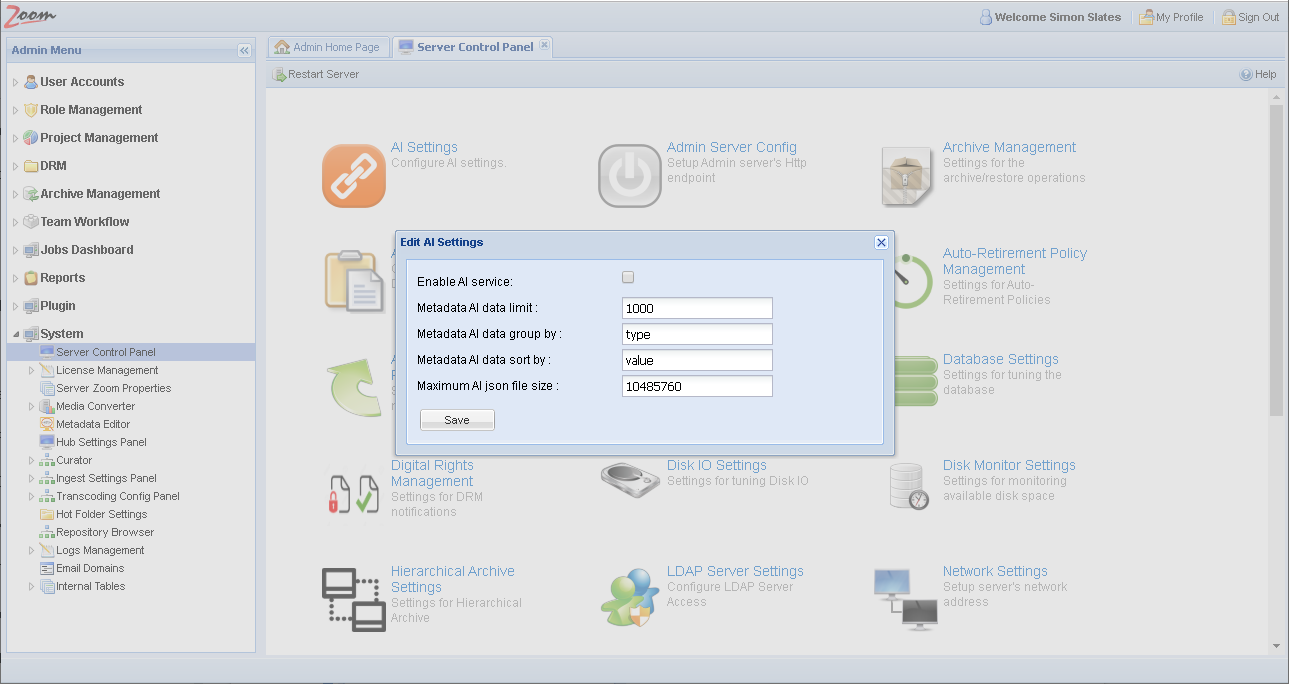
- Open the Server Control Panel under the System node again. Now, click AI Settings on the Server Control Panel page to finish configuring AI in Zoom.
- Usually, you do not need to modify the other AI settings. If needed, you can set these:
- Metadata AI data limit: controls the number of AI entries returned from the server in a single command for a single asset. Setting this value too high will affect the client’s performance. The default is 1000. It is recommended to set it to a higher value if you are not seeing all the results. This value can easily be set to 10000. When using video AI, it is recommended to set it to 10000.
- Metadata AI data group by: by default, Metadata AI data is grouped by AI Type. For Zoom 7.5, the only values supported are type and engineName. Please use the exact case for the AI data type.
- Metadata AI data sort by: by default, Metadata AI data is sorted by values present in them. For Zoom 7.5, only value is supported as the sorting order.
- Maximum AI json file size: controls the maximum amount of AI data that can be saved on the Zoom Server per asset in bytes. The default value is 10 megabytes (10485760 bytes) which is usually enough for storing 100,000 entries of AI data per asset.
- After updating the values, click Save. Click OK at the prompt.
- The AI settings are saved in Zoom.
Add Hub Configuration in Zoom
Zoom stores Hub configuration settings to connect with a Hub Server. These configuration values should be added to Zoom before installing the Hub Server.
Log in to the Web Management Console and click the Hub Settings Panel under the System node in the Admin Menu sidebar.
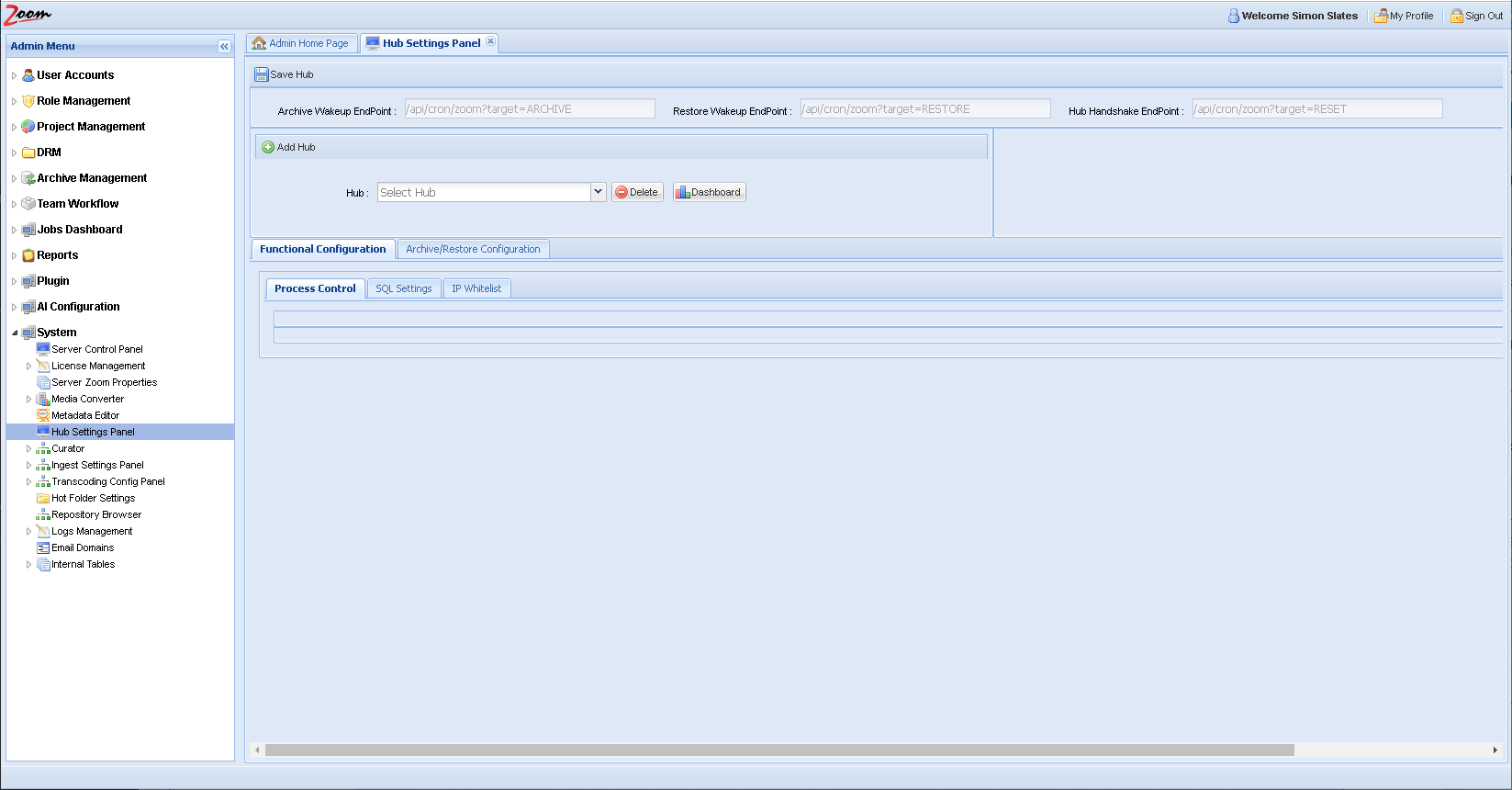
On the Hub Settings Panel, click Add Hub and specify a name for the new Hub. If you want to copy the settings of an existing Hub to your new Hub, select the existing Hub name from the Copy Configuration From Hub drop-down, otherwise leave it blank. Click Add.
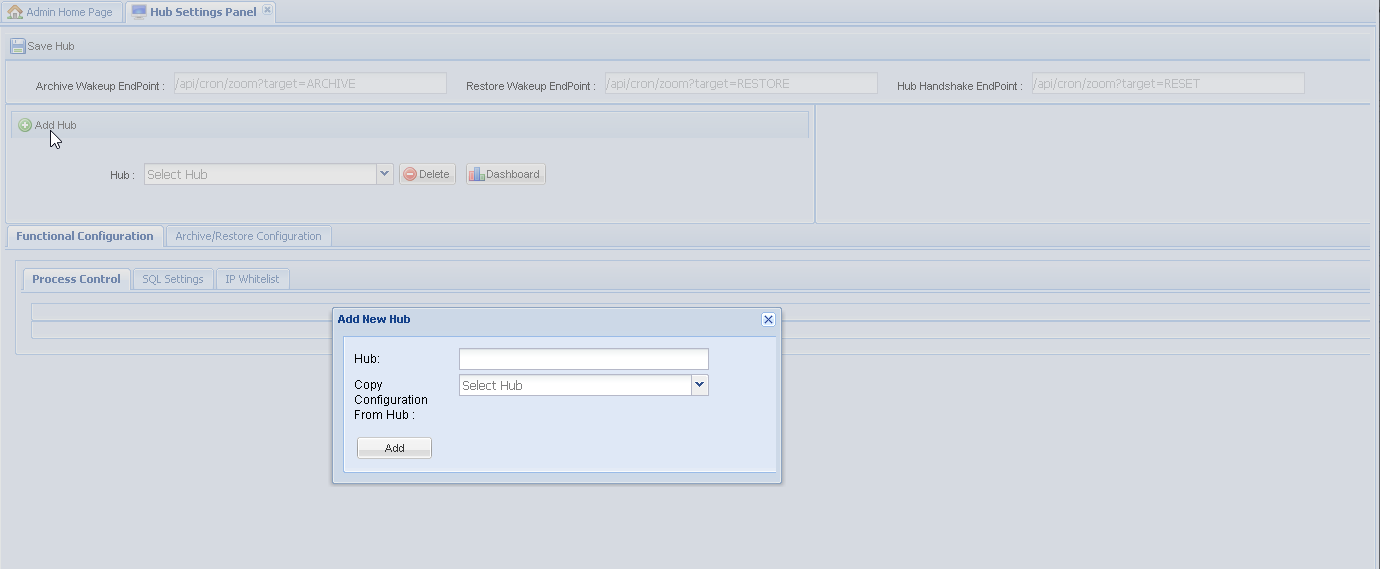
Update basic connectivity details for the Hub, like Host (IP) and Port settings. For location-specific settings, also specify the location where the Hub should work. If using SSL, select the Enable Secure Hub Connection checkbox.
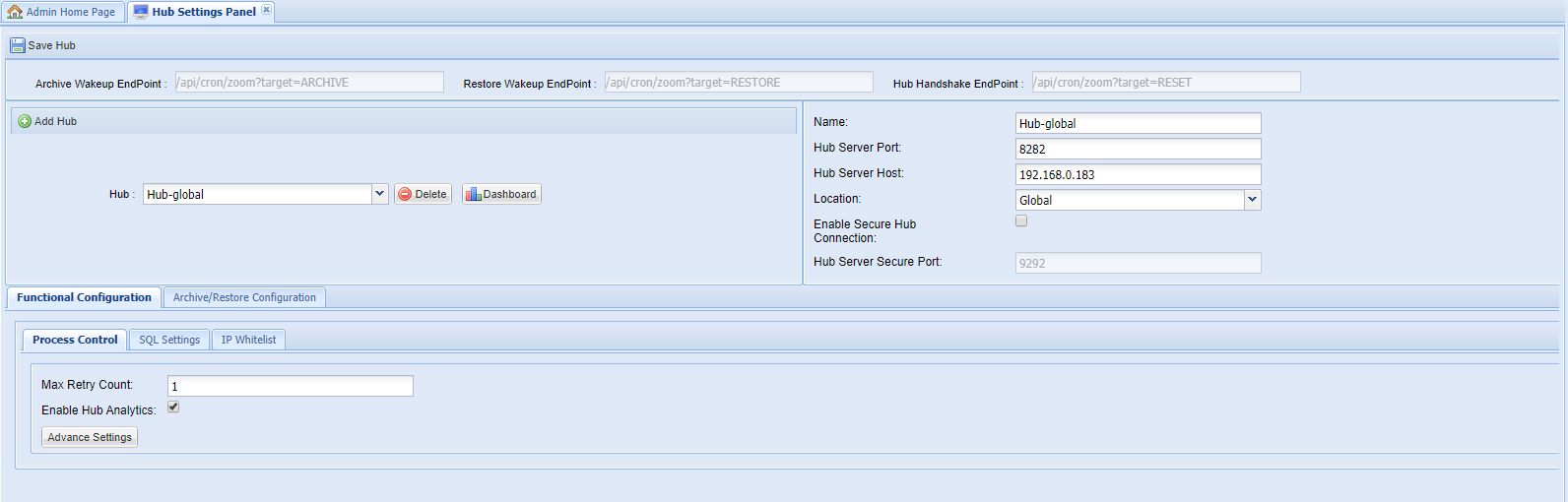
Once the basic connectivity parameters are specified, enter values for the advanced configuration. It is categorized into two parts namely the Functional Configuration and the Archive/Restore Configuration. See the sections below to know about the values that should be entered for these:
Functional Configuration
These values are needed for the basic working of the Hub. It covers Process Control values, SQL DB values, and IP Whitelisting values.
SQL Settings
Hub uses a SQL Server to store job-related details.

The Zoom Server also uses SQL to store process data for some of its other modules too. If it is already configured for your Transcoder and you would like to use the same SQL database for the Hub as well, then simply select the Use Same as Transcoder option. If you want to create a new or separate SQL database for the Hub, then follow instructions here to download your OS-specific installer of MySQL. Run the installer and follow the instructions. Create a user and provide the host, username, password, driver (com.mysql.cj.jdbc.Driver) details here.
Click Save Hub after configuring the necessary details.

Set up the Hub Server
You need the Hub Server to manage jobs for various Zoom modules like Hierarchical Archive or AI.
You can install it on any server in your Zoom network. Check that you have the Hub installer from Evolphin Support before proceeding.
Installing the Hub
Extract the shared Hub installer zip/tar to any path on your designated Hub Server machine and follow the steps below to install the Hub:
On Windows
- Open Command Line as an administrator.
- Navigate to the \bin folder inside the extracted Hub build files.
- Run Hub install (this will register Evolphin Job Hub as a service)
- Run Hub start (this will start the Hub Server)
To stop use Hub stop; for restart use Hub restart. To remove this service use Hub remove.
On Linux
- Navigate to the /bin folder inside the extracted Hub build files.
- Run ./Hub start (this will start Hub server)
To stop use ./Hub stop, for restart use ./Hub restart and to remove this service use ./Hub remove.
Registering with Zoom
After installing the Hub using the steps above, you also need to update one or more XML files with the correct configuration before registering with Zoom. When you start the Hub for the first time then it is registered with Zoom using the configuration settings in these XML files. Follow these steps on your Hub machine:
- Navigate to the /conf folder inside the folder where you have installed the Hub and locate hub.xml.
- Open hub.xml for editing.
<JobHubServerSpec>
<host>localhost</host>
<port>8282</port>
<configPort>7272</configPort>
<stagingArea>C:\EJH\staging</stagingArea>
<enableDebug>false</enableDebug>
<hubName>GlobalHub</hubName>
<s3MultipartUploadThreshold>5242881</s3MultipartUploadThreshold>
<s3MultipartUploadThreadCount>5</s3MultipartUploadThreadCount>
<ZoomSpec>
<adminServer>http://localhost:8443</adminServer>
<zoomUser></zoomUser>
<zoomPassword></zoomPassword>
<tpmPrefix>TPM:</tpmPrefix>>
</ZoomSpec>
</JobHubServerSpec> - Update these tags as needed:
- hubName: specify the name for this Hub as given in the Web Management Console.
- host: check that it has the IP/hostname for the Hub Server machine.
- adminServer: specify Zoom Server’s URL with port used for Web Management Console.
- zoomUser and zoomPassword: specify a dedicated Zoom user account and password here for use by this Hub machine.
- Save and close hub.xml.
- In the same /conf folder, locate ai-spec.xml.
- Open ai-spec.xml for editing.
- Update the tag previewServerUrl with the URL to access Preview Server, that is hostname with the port. For example, <previewServerUrl>http://192.168.0.183:8873</previewServerUrl>.
- Save and close ai-spec.xml.
- Start the Hub service (check Starting and Stopping Zoom Services (Linux) or Starting and Stopping Zoom Services (Windows) to know more about starting this service).
The Hub is now registered with Zoom. If needed, you can modify these settings here in the XML files and update other Hub configuration parameters through the Zoom Web Management Console. However, you need to restart Hub service after any change to Hub parameters is made (in the XML files or in Zoom Web Management Console).
In particular, the DB settings could be updated using the file db-config.properties.
Open the conf folder inside the Hub installation directory. Inside the conf folder, locate db-config.properties. The values for these properties should be set:
- jdbc.url – URL of your SQL Server with the port.
- jdbc.user – Username of the SQL server. This user must have full access to the SQL server at least to the database named hub.
- jdbc.password – Password of the SQL user.
- jdbc.param –
Save the file and restart the Hub.
Configure Veritone AI Settings on the Hub Server
If you are using Veritone as an AI Provider, you need to configure it on the Hub Server.
Once you have configured Hub in Zoom and installed your Hub Server, you can add Veritone settings to it.
Start the Hub Server where you want to run AI jobs. On this Hub Server, open the conf folder inside the Hub installation directory. Inside the conf folder, locate ai-spec.xml.
<ScratchDirSpec>
<scratchDir>/home/evolphin/.ejh/tmp/ai</scratchDir>
</ScratchDirSpec>
<ExecutorSpec>
<maxThreadCount>4</maxThreadCount>
<maxRetryCount>5</maxRetryCount>
<TimeoutSpec>
<timeout>60</timeout>
<timeUnit>SECONDS</timeUnit>
</TimeoutSpec>
<queueSize>100</queueSize>
</ExecutorSpec>
<previewServerUrl>http://localhost:8873</previewServerUrl>
<PreviewFetchHttpCallTimeout>
<timeout>60</timeout>
<timeUnit>SECONDS</timeUnit>
</PreviewFetchHttpCallTimeout>
<RekognitionSpec>
<defaultMaxLabel>100</defaultMaxLabel>
<defaultMinConfidence>0.5</defaultMinConfidence>
<awsDefaultRegion>us-west-2</awsDefaultRegion>
</RekognitionSpec>
<batchSize>100</batchSize>
<VeritoneSpec>
<queriesDirectory>veritone-queries</queriesDirectory>
<awsAccessKeyId>XYZ</awsAccessKeyId>
<secretAccessKey>ABCDEF</secretAccessKey>
<bucketName>buckername</bucketName>
<region>bucker-region</region>
<defaultPublicLinkExpiryInDays>7</defaultPublicLinkExpiryInDays>
<defaultMinConfidence>0.0</defaultMinConfidence>
<minimumValueLength>0</minimumValueLength>
<maximumVeritoneJobs>2</maximumVeritoneJobs>
</VeritoneSpec>
<AiJobCountLimits>
<amazonAiProviderLimit>0</amazonAiProviderLimit>
<veritoneAiProviderLimit>10</veritoneAiProviderLimit>
</AiJobCountLimits>
<rrnToStartPollingFrom>0</rrnToStartPollingFrom>
</AiSpec>
You need to set a few tags here:
- scratchDir – set this for a temporary directory which is used to hold data in an intermediate state. For example, file proxies are kept in this directory until they are sent for AI analysis. Another use of it is to store AI data in the intermediate state. It is recommended to point this directory to a large storage volume where hundreds of proxy files can be stored easily. These files will be removed after completion of a job, but enough space should be provisioned for the intermediate time.
- maxThreadCount – set this for the maximum number of AI jobs that can be executed in parallel.
- maxRetryCount- set this for the maximum number of times a job should be retried on failure before marking it as failed.
- previewServerUrl – this tag should point to your Preview Server’s URL. Without populating this tag, the Hub will not be able to download the proxies for AI analysis.
- bucketName inside veritoneSpec – you need to specify the name of the S3 bucket for storing proxies for AI analysis. The hub needs a temporary staging S3 bucket to upload and store proxies. This is only required when Veritone is used as an AI connector.
- awsAccessKeyId inside veritoneSpec – specify the Access Key ID for the S3 bucket specified above.
- secretAccessKey inside veritoneSpec – specify the Secret Access Key for accessing the S3 bucket.
- region – set the AWS region where the S3 bucket is hosted.
- defaultPublicLinkExpiryInDays – set this as the number of days after which data will auto clean from the S3 bucket. This is the same as the number of days configured for the expiration rule on this bucket inside lifecycle rules. It is recommended to set it to 7 days.
- maximumVeritoneJobs – controls the maximum number of Veritone AI jobs to run at one time. If these many jobs are running on Veritone, no further jobs will be scheduled.
- veritoneAiProviderLimit – set this property to limit the total number of jobs that the Hub will send to Veritone AI for processing. The Hub will stop processing more files after reaching this limit. This is used to prevent going over the allotted number of jobs for billing purposes.
Optional advanced settings:
- rrnToStartPollingFrom – set this value to the RRN from where the system should start scanning from. When this value is 0 or not set, new asset scanning starts from the first RRN. This change is only needed if you do not want to scan the whole repository with AI but only assets added on and after a specific RRN. RRN is the Repository Revision Number, the transaction number that is generated for each change to the Zoom repository. There would be one or more assets added, updated, or deleted together for a single RRN. You can fetch the RRN by searching for Repo Revision metadata property under File Properties for the asset in the Asset Browser.
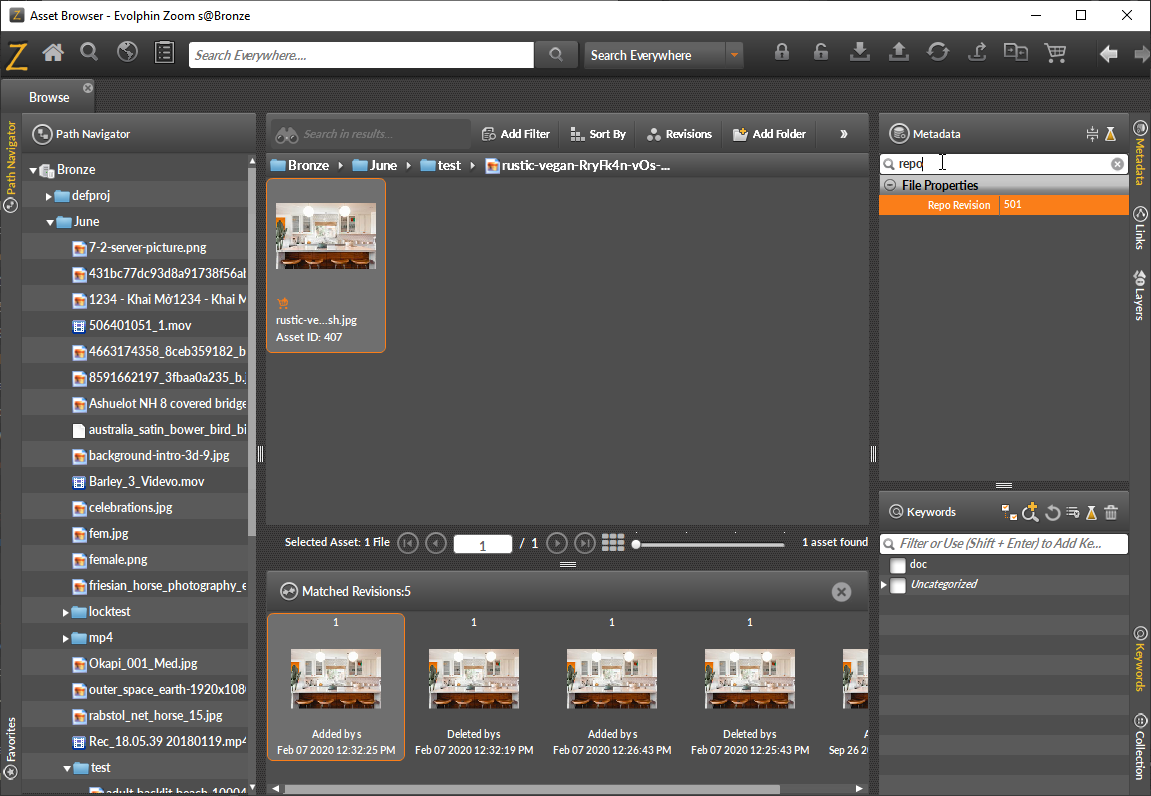
Save and close the file.
Restart your Hub by running Hub restart from the bin folder inside Hub’s installation directory.
Configure Amazon AI Settings on the Hub Server
If you are using Amazon as an AI Provider, you need to configure it on the Hub Server.
Once you have configured Hub in Zoom and installed your Hub Server, you can add Amazon settings to it.
Start the Hub Server where you want to run AI jobs. On this Hub Server, open the conf folder inside the Hub installation directory. Inside the conf folder, locate ai-spec.xml.
<ScratchDirSpec>
<scratchDir>/home/evolphin/.ejh/tmp/ai</scratchDir>
</ScratchDirSpec>
<ExecutorSpec>
<maxThreadCount>4</maxThreadCount>
<maxRetryCount>5</maxRetryCount>
<TimeoutSpec>
<timeout>60</timeout>
<timeUnit>SECONDS</timeUnit>
</TimeoutSpec>
<queueSize>100</queueSize>
</ExecutorSpec>
<previewServerUrl>http://localhost:8873</previewServerUrl>
<PreviewFetchHttpCallTimeout>
<timeout>60</timeout>
<timeUnit>SECONDS</timeUnit>
</PreviewFetchHttpCallTimeout>
<RekognitionSpec>
<defaultMaxLabel>100</defaultMaxLabel>
<defaultMinConfidence>0.5</defaultMinConfidence>
<awsDefaultRegion>us-west-2</awsDefaultRegion>
</RekognitionSpec>
<batchSize>100</batchSize>
<VeritoneSpec>
<queriesDirectory>veritone-queries</queriesDirectory>
<awsAccessKeyId>XYZ</awsAccessKeyId>
<secretAccessKey>ABCDEF</secretAccessKey>
<bucketName>buckername</bucketName>
<region>bucker-region</region>
<defaultPublicLinkExpiryInDays>7</defaultPublicLinkExpiryInDays>
<defaultMinConfidence>0.0</defaultMinConfidence>
<minimumValueLength>0</minimumValueLength>
<maximumVeritoneJobs>2</maximumVeritoneJobs>
</VeritoneSpec>
<AiJobCountLimits>
<amazonAiProviderLimit>0</amazonAiProviderLimit>
<veritoneAiProviderLimit>10</veritoneAiProviderLimit>
</AiJobCountLimits>
<rrnToStartPollingFrom>0</rrnToStartPollingFrom>
</AiSpec>
You need to set one tag here:
- amazonAiProviderLimit – set this property to limit the total number of jobs that the Hub will send to Amazon AI for processing. The Hub will stop processing more files after reaching this limit. This is used to prevent going over the allotted number of jobs for billing purposes.
Optional advanced settings:
- rrnToStartPollingFrom – set this value to the RRN from where the system should start scanning from. When this value is 0 or not set, new asset scanning starts from the first RRN. This change is only needed if you do not want to scan the whole repository with AI but only assets added on and after a specific RRN. RRN is the Repository Revision Number, the transaction number that is generated for each change to the Zoom repository. There would be one or more assets added, updated, or deleted together for a single RRN. You can fetch the RRN by searching for Repo Revision metadata property under File Properties for the asset in the Asset Browser.
Save and close the file.
Restart your Hub by running Hub restart from the bin folder inside Hub’s installation directory.
Configure Veritone AI in Zoom
To finish configuring Veritone AI Provider, you also need to set it up on your Zoom Server.
After setting up the Hub Server and configuring Veritone settings on it, we also need to configure detailed Veritone AI parameters in Zoom using the Web Management Console. We need to set Veritone as the AI Provider, provide configurations for AI engines, and then map AI rules to AI engines. Follow these steps:
AI Providers
You need to add one or more AI providers to work with Zoom. Follow these steps to add a provider:
- Log in to the Web Management Console and click AI Providers under the AI Configuration node in the Admin Menu sidebar. You need to add an AI Provider here.
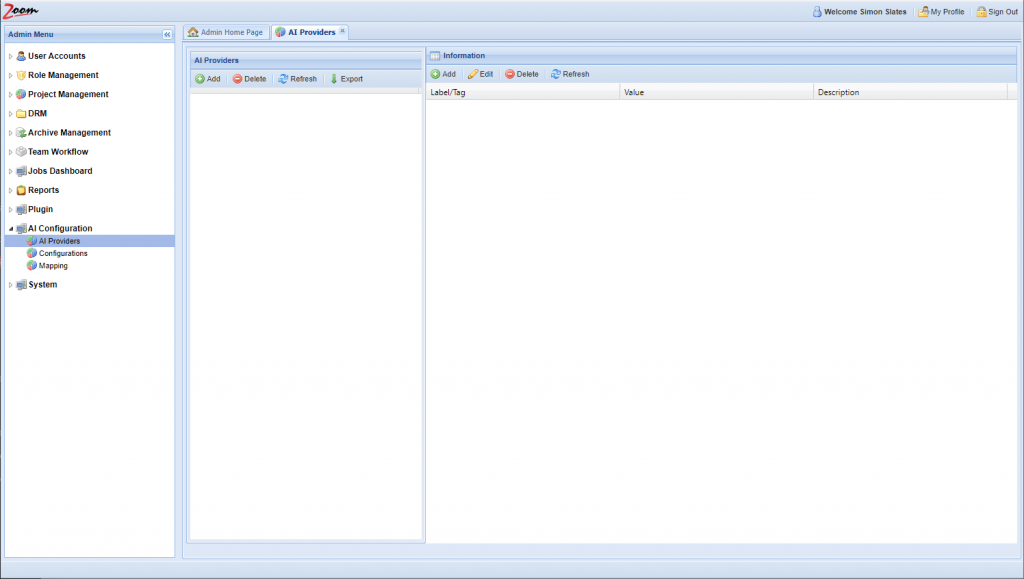
- Inside the AI Providers panel, click Add and choose Veritone from the list of AI Providers.
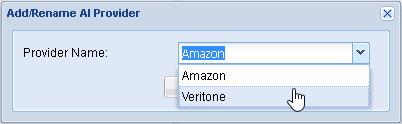
- Select the newly added row for Veritone. Its details will be loaded in the right side Information panel.
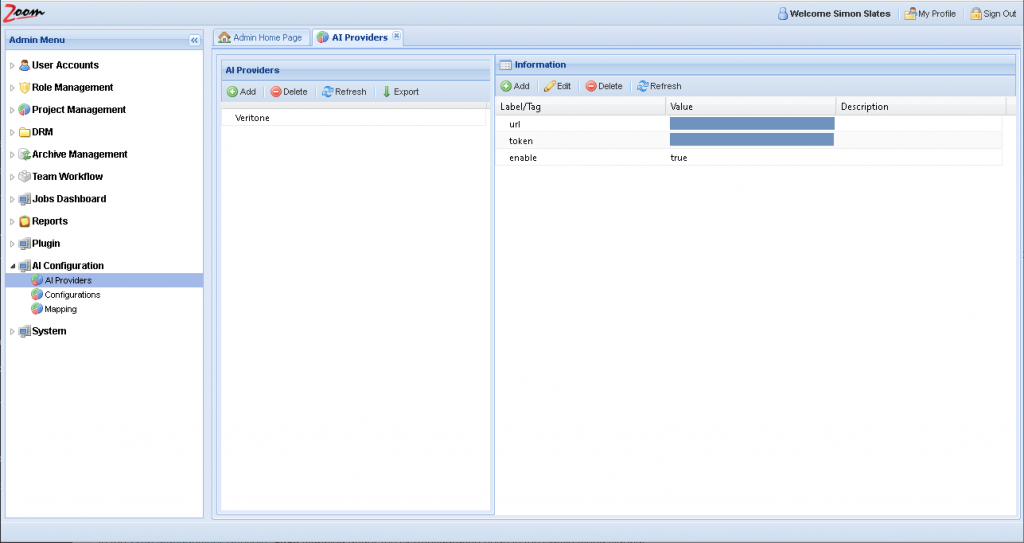
- Add/update these values in the Information Panel:
- url – enter the URL to access Veritone services. It should be the exact value given by Veritone. For example, https://uk.api.veritone.com/v3/graphql
- token – specify the API token which will be used for authentication with Veritone. Without the token, Zoom can not authenticate to access AI services. The Veritone API token is generated from Veritone’s user interface. For more details, check Veritone’s documentation at https://docs.veritone.com/#/apis/authentication.
- enable – this is true by default to enable this provider. Setting this value to false will disable this provider in Zoom, so it will not be used further. If this value is missing in the configuration files, it will still be treated as true.
The values specified here are all case-sensitive.For other providers, different sets of values may be needed.
- After updating the provider values, move to configure this provider on the AI Configurations page in the next section.
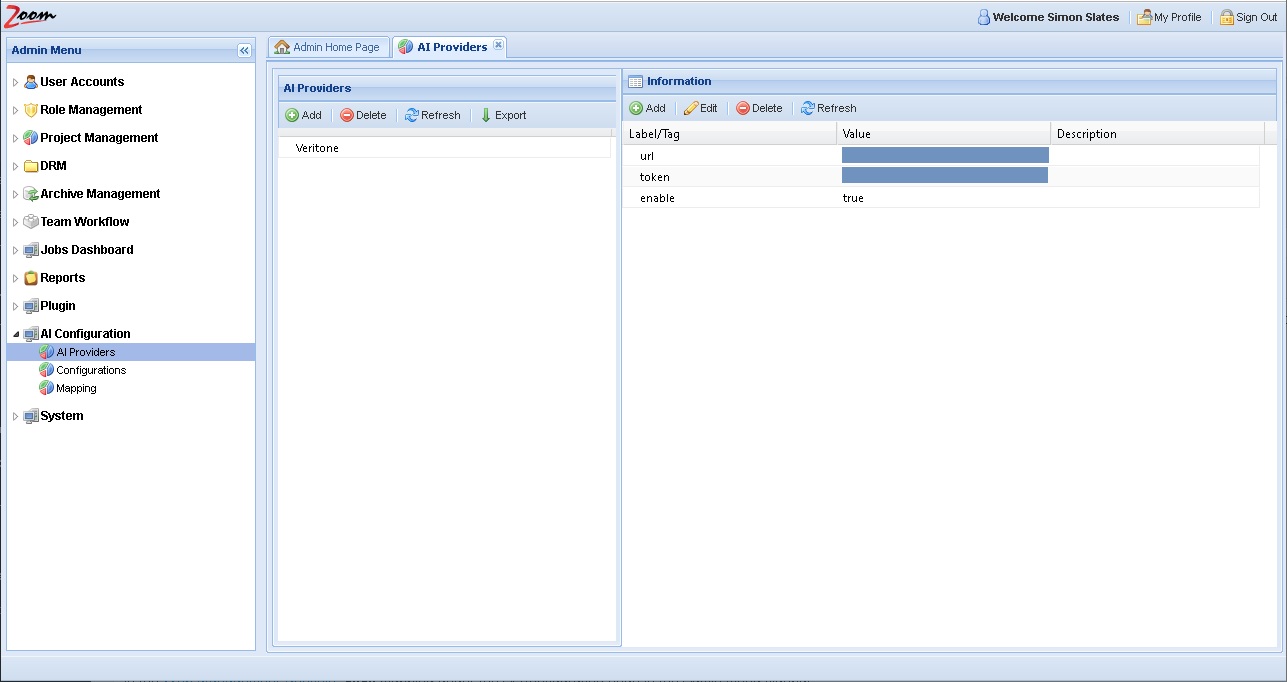
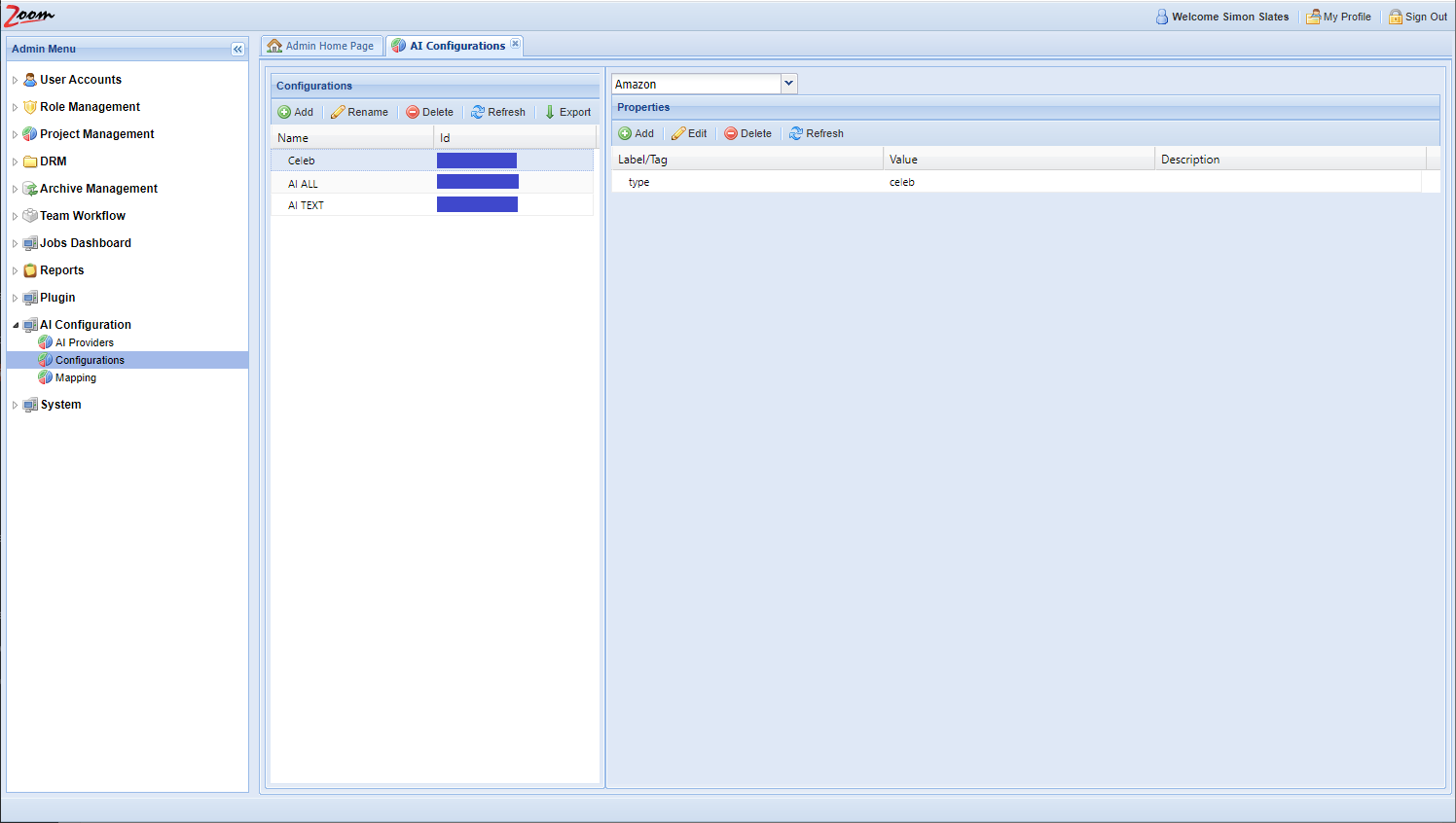
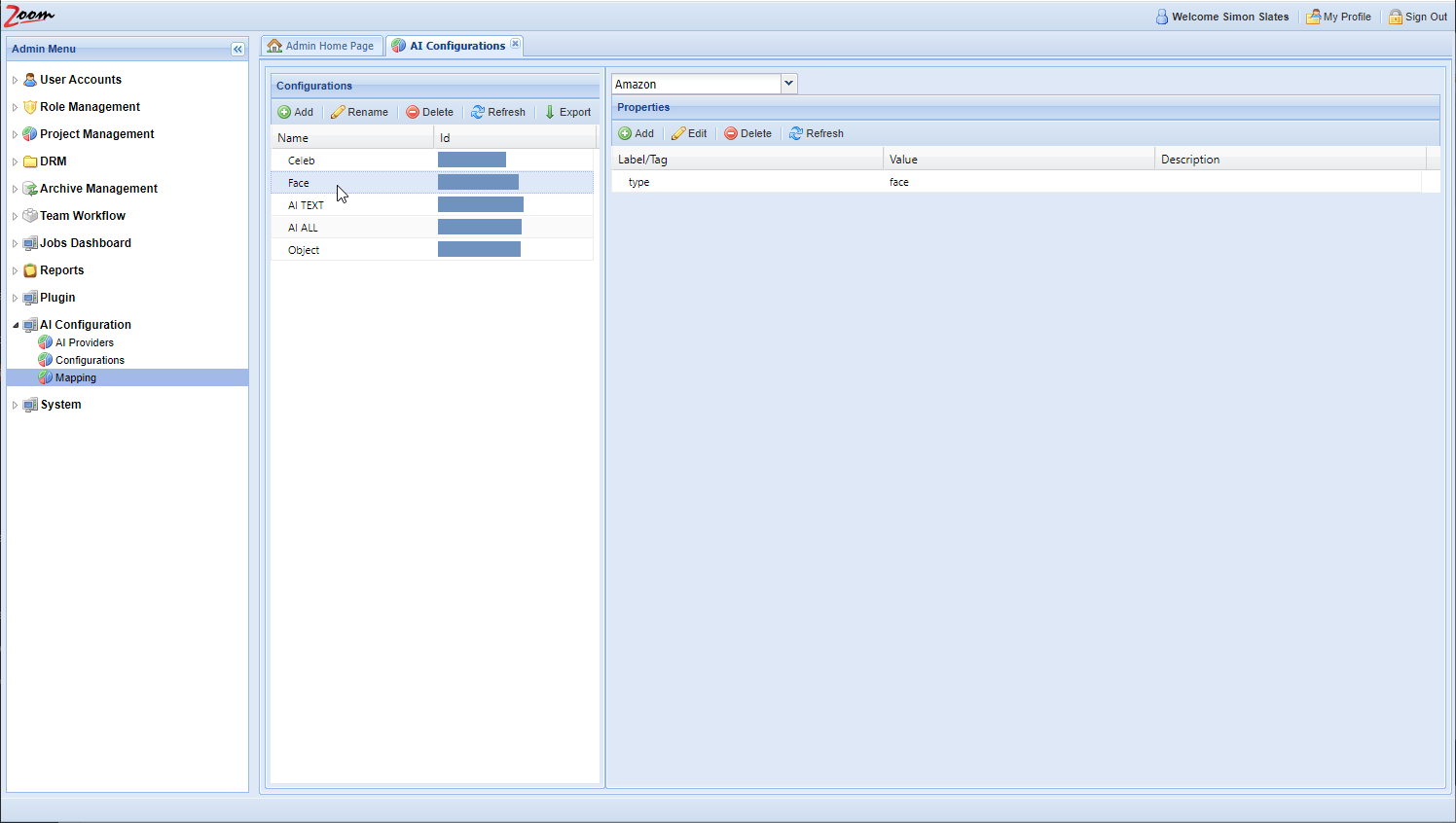
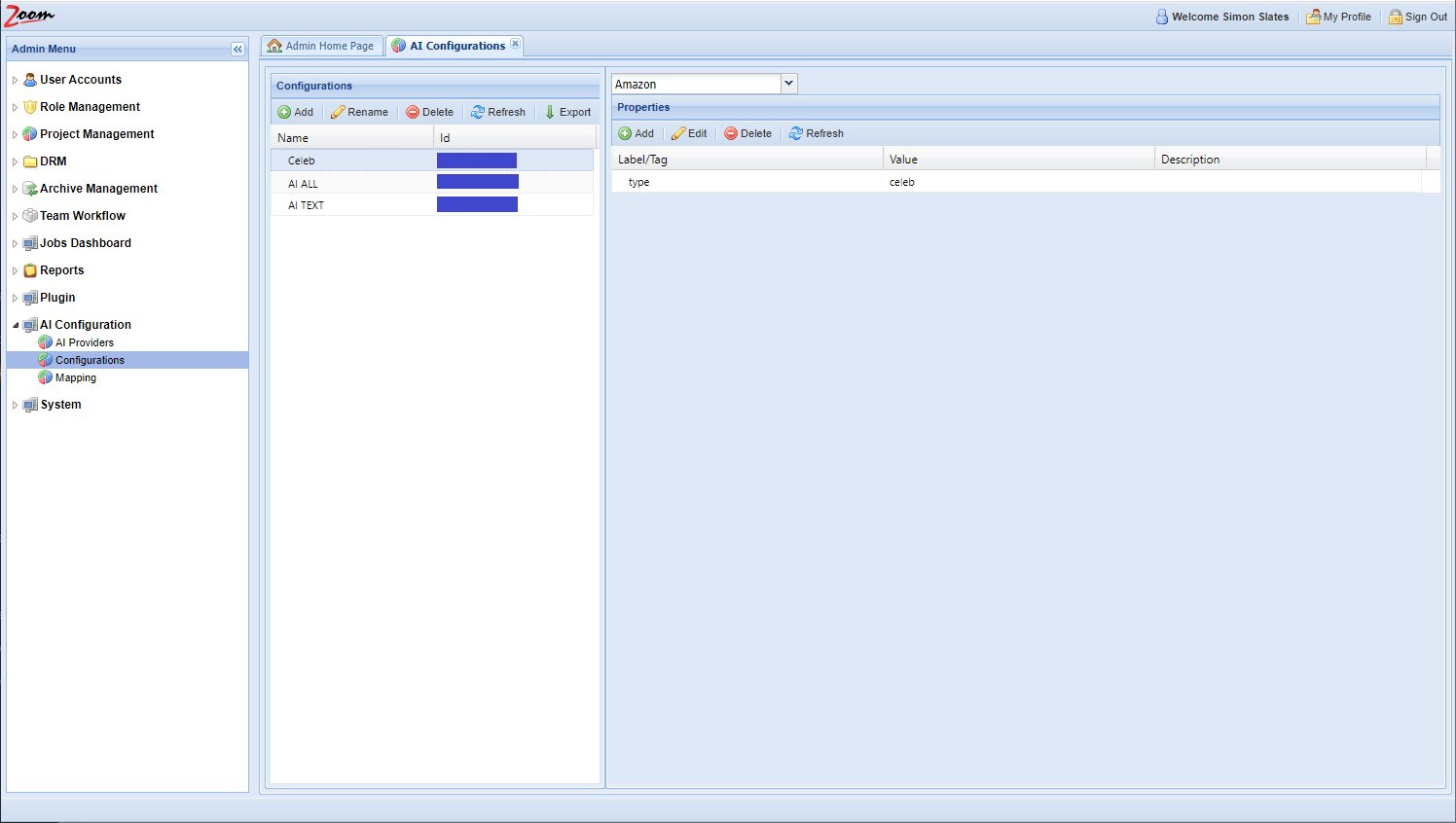
AI Configurations
You need to add one configuration per AI Engine provided by your AI Provider. You would get the Engine ID and type from them for each AI engine. Follow these steps to add the necessary configurations:
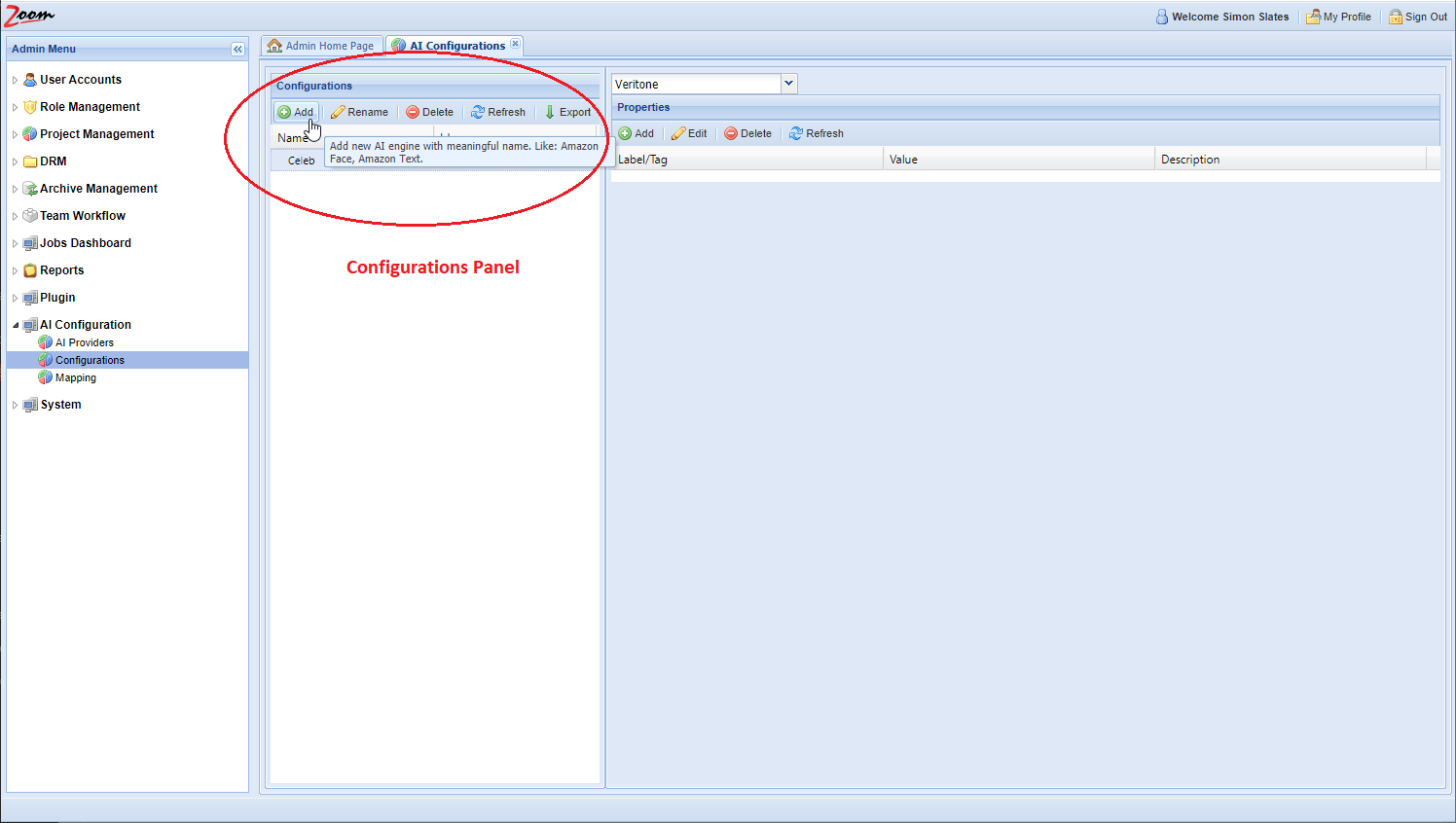
- In the Web Management Console, click Configurations under the AI Configuration node in the Admin Menu sidebar. You need to add AI configurations here.
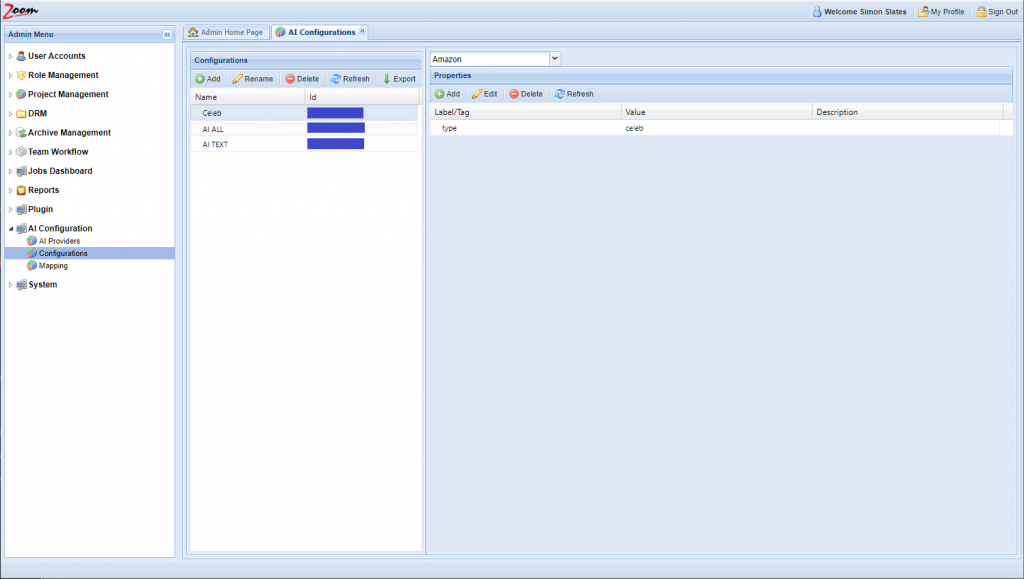
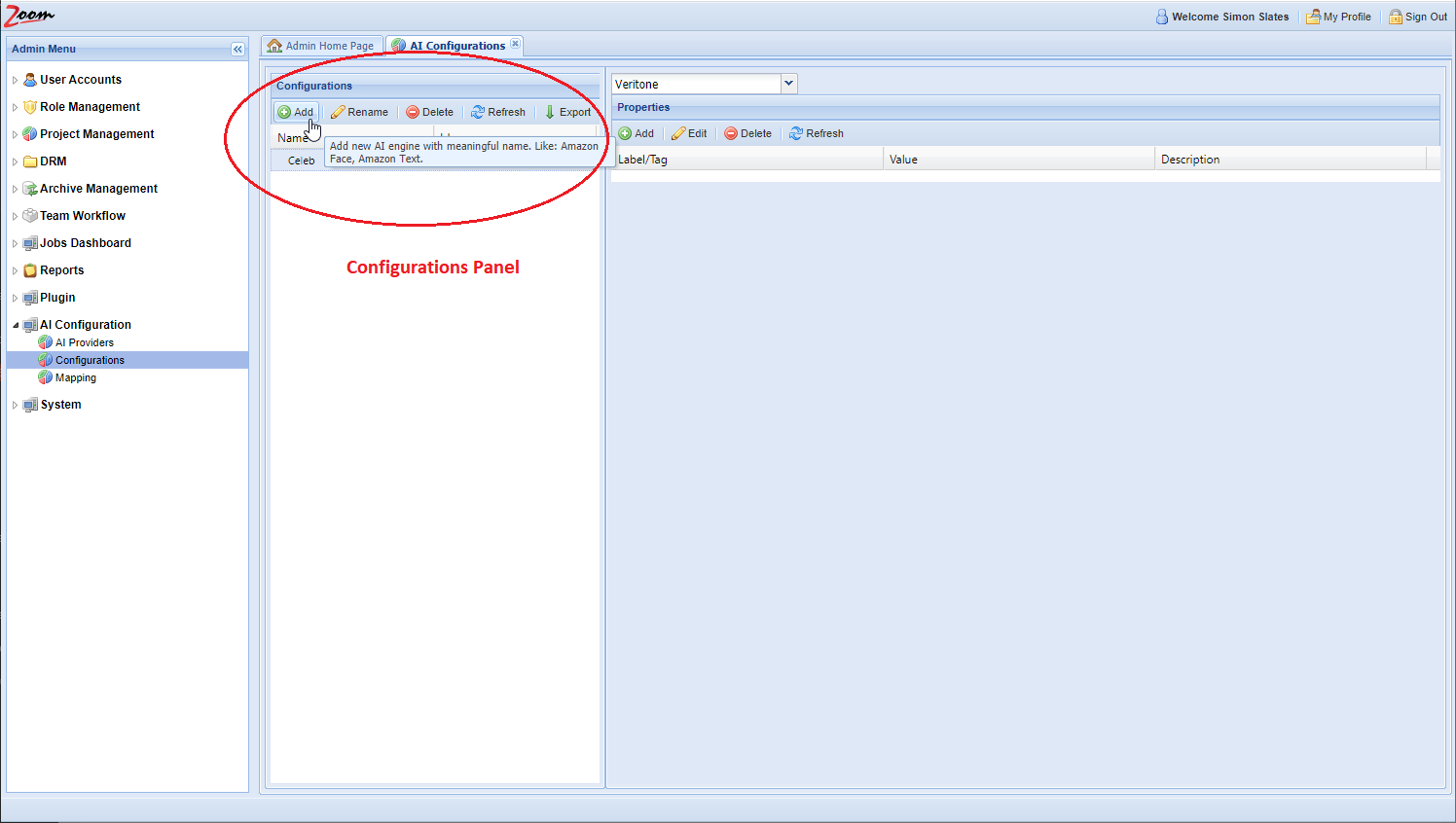
- Inside the Configurations panel, click Add to add a new configuration.
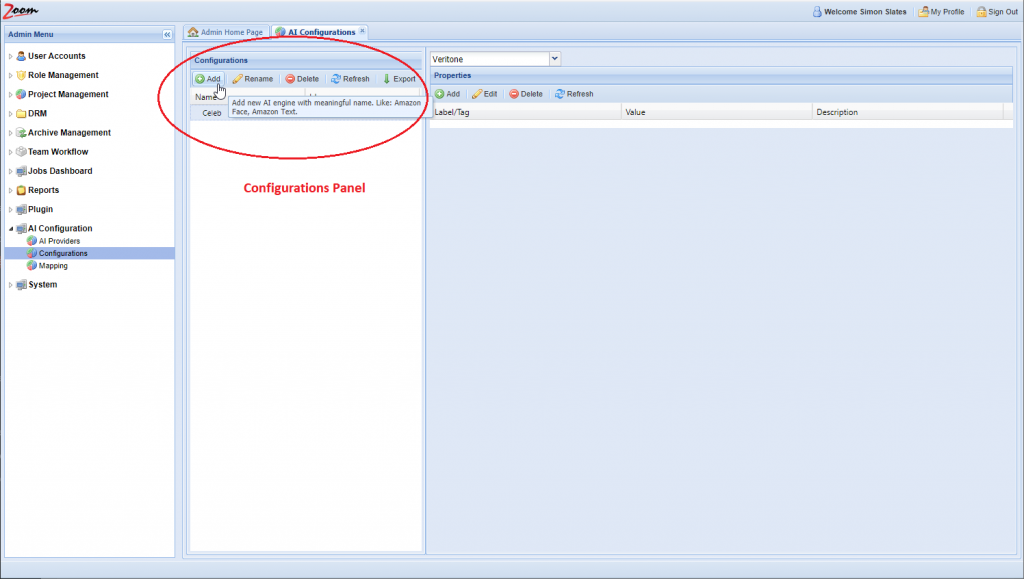
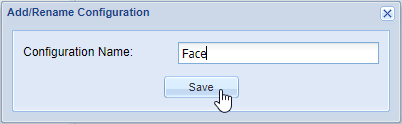
- Provide a name for the new configuration. It is best to use names relating to the task performed by the engine and the names should be unique.
- Select the newly added row for the new configuration. Its details will be loaded in the right side Properties panel.
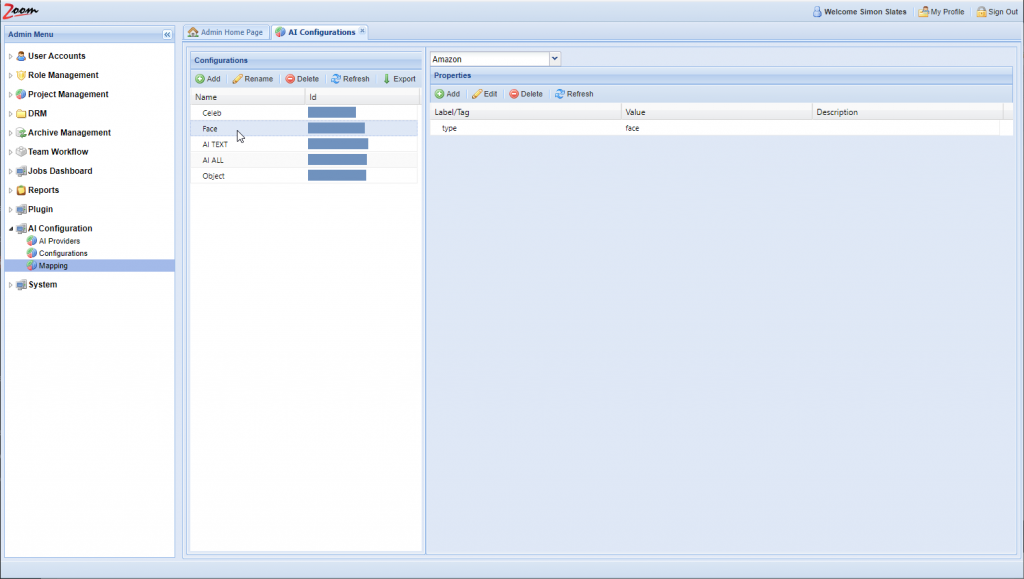
- Choose an AI provider from the AI Providers dropdown box above the Properties panel. Choose the provider, Veritone, that we had added in the previous section.
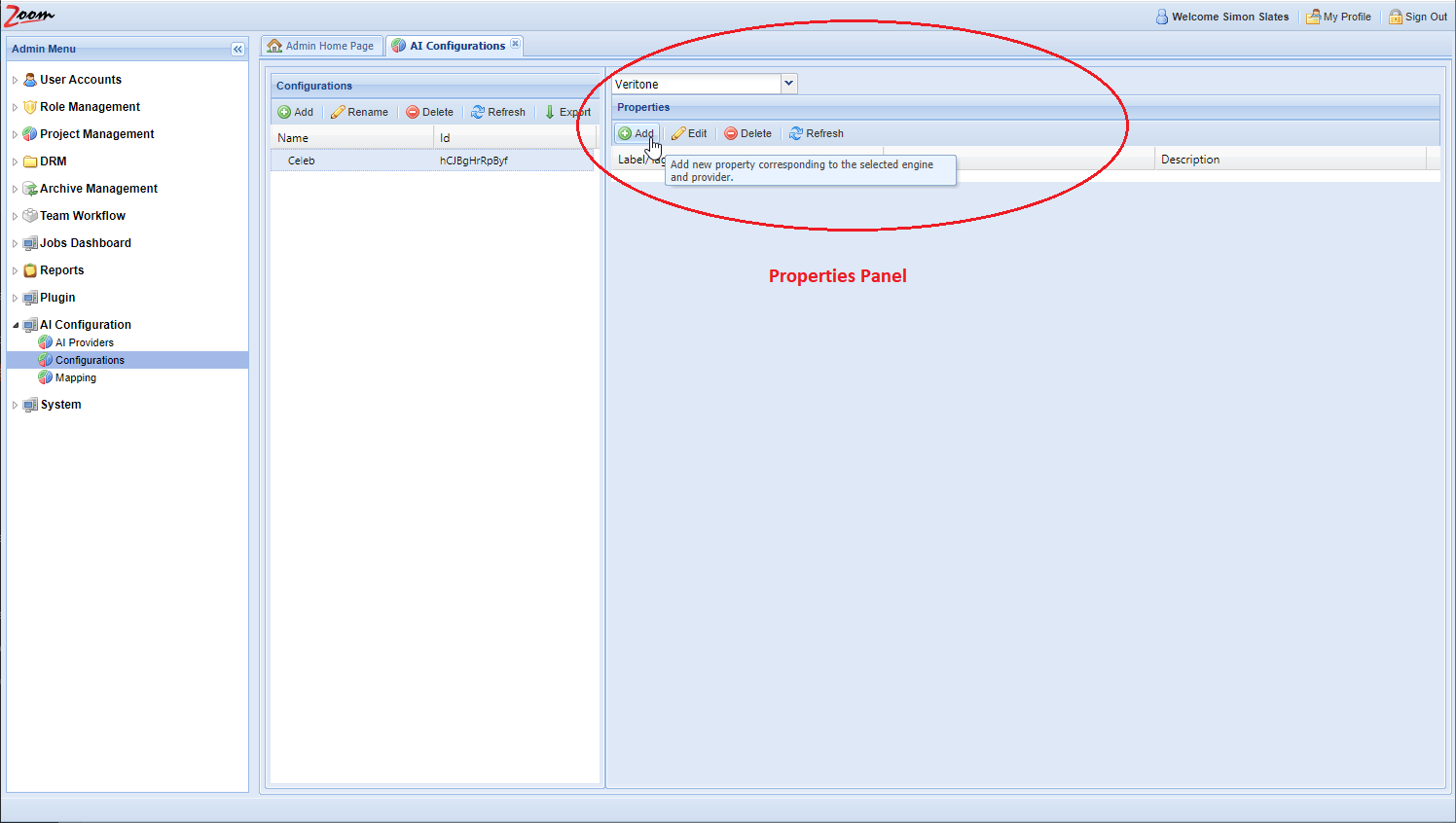
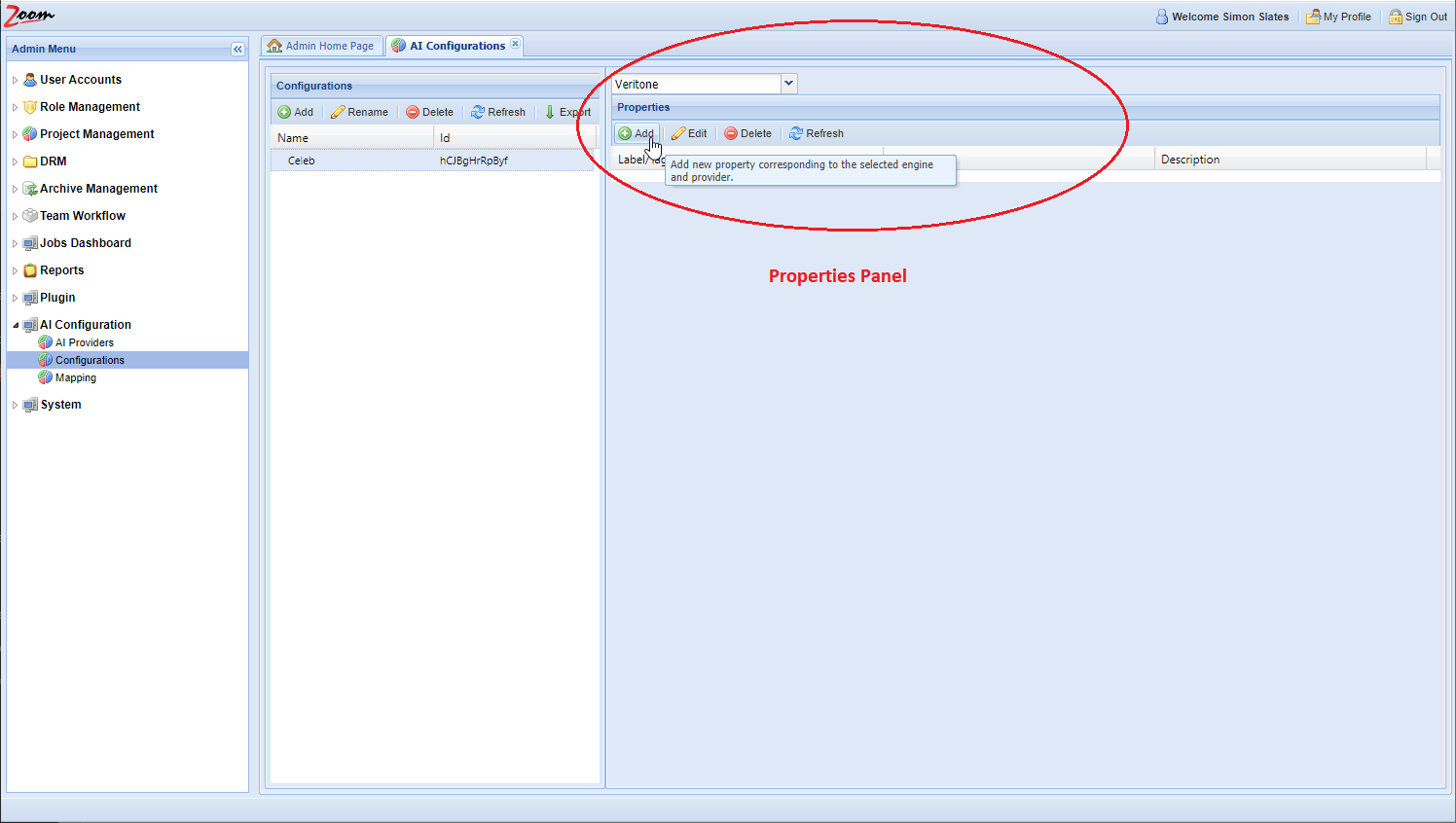
- Click Add in the Properties panel for each property that you want to add for the new AI Configuration.
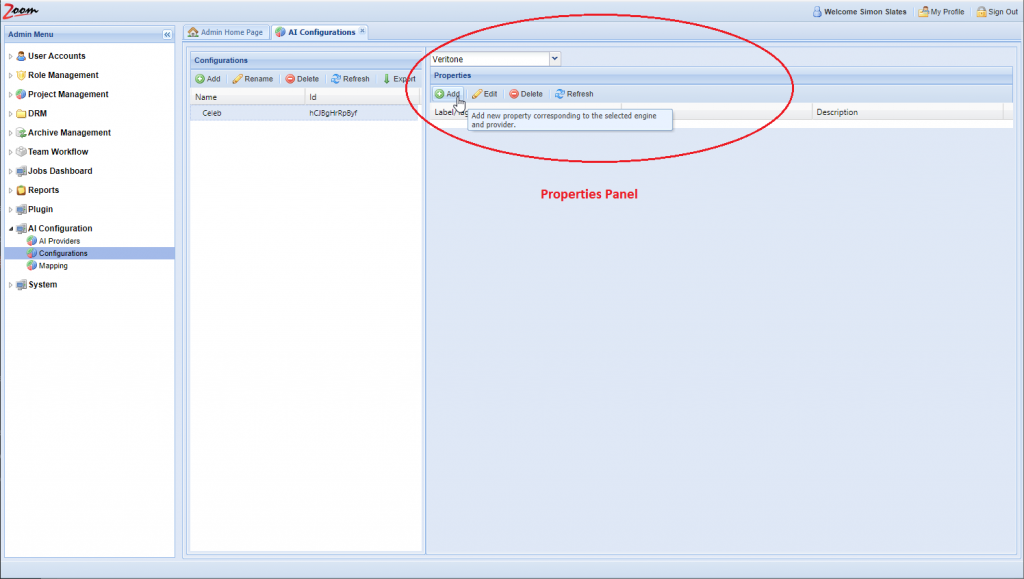
- You need to fill Label and Value for each property at the minimum. The Description is optional.
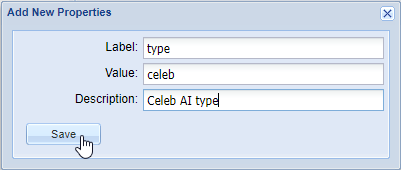 For example, for the AI Type property, you should add the Label as type and Value as its AI type. So, Label will be type and Value may be transcription.
For example, for the AI Type property, you should add the Label as type and Value as its AI type. So, Label will be type and Value may be transcription. - Each configuration that you add should have exactly one AI Engine and one AI Type property in it. Some configurations will also need additional properties depending on the AI Engine that is being configured. Each group of AI Engine and AI Type together should be exclusively configured in one configuration only, and these cannot be repeated. Add these properties for the new configuration:
Label Value type Add the AI type that should be associated with this configuration. This is the AI Engine’s AI Type that is provided by Veritone. veritoneEngineId Add the engine ID that will be associated with this configuration. It should be the exact same value as provided by Veritone. payload:libraryId Specify the Library ID if it is required by your AI engine. The given library will be passed as an argument to the engine. Libraries are used at Veritone to train engines to look for specific faces, celebrities, logos, or objects to identify in the footage. payload:<key> Specify this property if there is a need to pass extra arguments to the engine. To create an argument for an engine, prefix it with payload: (payload + colon). For example, to pass a debug=true argument to the engine, the Label should be entered as payload:debug. The value should be true.enable Optionally, set this property to false to disable this AI Engine. The Engine will be disabled and no further jobs will be created using this AI Engine. Similarly, setting ‘enable’ as false for an AI Provider will disable that provider and all the engines associated with it.minConfidence Specify the confidence level in the range from 0.00 to 1.00. Only data that has a confidence level equal or higher will be added to the Zoom database. The rest will be discarded. The default value of 0 is used when this property is not specified. minimumValueLength Specify the minimum length of value to save with Zoom. Any value which has a lesser number of characters than this value will be ignored. The default value is 0, meaning all values from Veritone AI engines are pushed and saved with the Zoom server. This default is used when no value is set for this property. maxJoinWords Specify this property to join AI data sent by the AI Engine. Sometimes, AI data is too granular, such as with transcription engines returning one word every few milliseconds. Using this property, we can join the AI data every few words. This value has to be greater than one to have any effect. maxJoinWordsRange Similar to maxJoinWords, specify this property to join AI data based on the number of seconds elapsed. Its value has to be greater than one to have any effect. type and veritoneEngineId should be specified for each AI Engine.payload:libraryId and payload:<key> are also mandatory when extra values need to be passed to the AI Engine.
enable, minConfidence, minimumValueLength, maxJoinWords, and maxJoinWordsRange are optional. All property values specified are case-sensitive.maxJoinWords or maxJoinWordsRange work for any AI engine, not just transcription. - After updating the configurations for the AI engines inside your AI provider, move to map the engines with configurations on the AI-Mappings page in the next section.
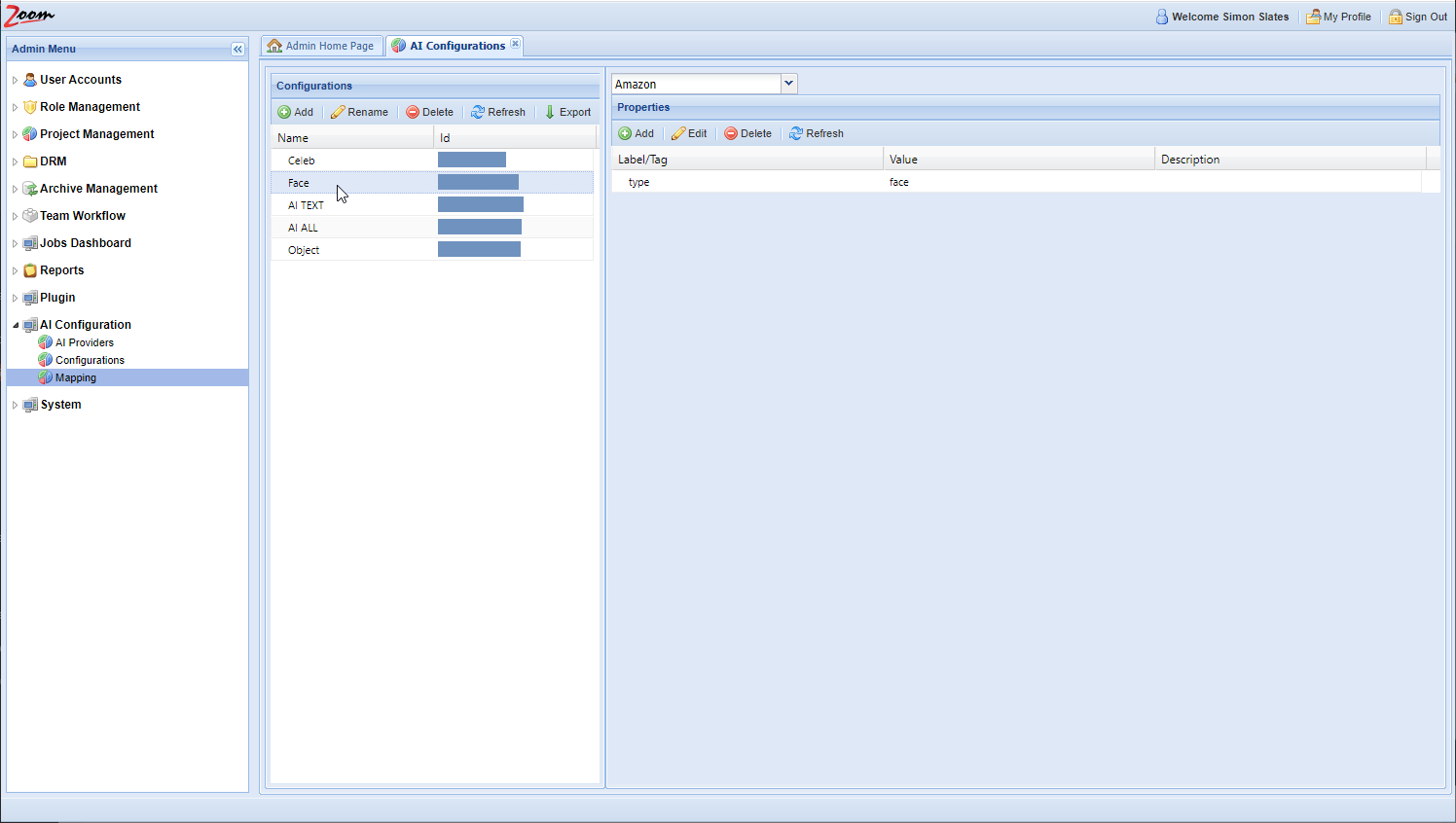
AI-Mapping
Finally, you need to map AI engines with Zoom, to control what assets will be analyzed by each engine. Follow these steps to map asset rules to an engine:
- In the Web Management Console, click Mapping under the AI Configuration node in the Admin Menu sidebar.
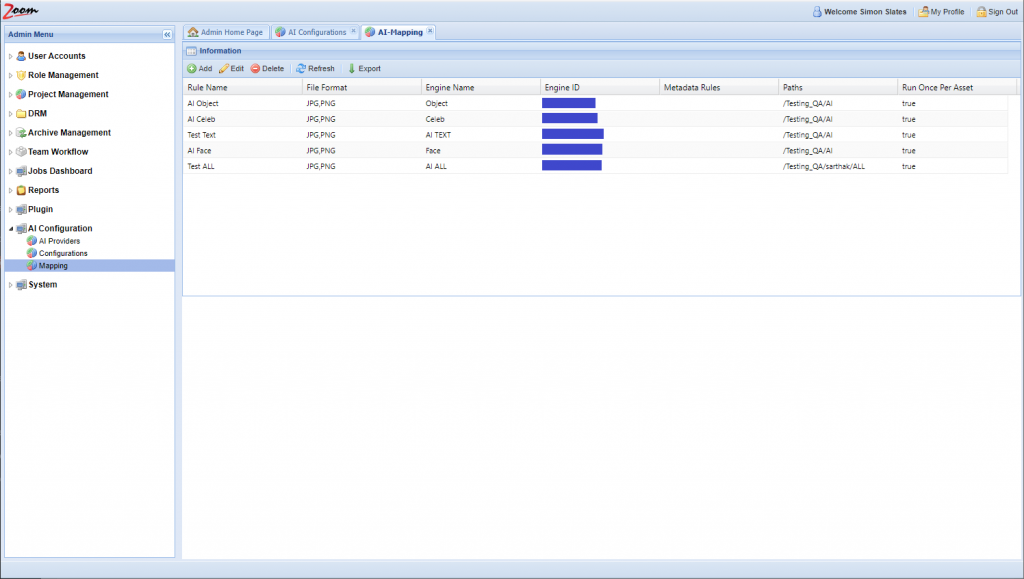
- Click Add to add a new mapping rule.

- Specify these values:
- Rule Name: specify a name for the mapping rule.
- File Format: specify a comma-separated list of file extensions associated with this mapping. For e.g.: MP4, MXF. Only files matching the given extension(s) will be sent for analysis to the AI Engine. If not specified, then all file types are considered valid for this mapping.
- Engine: choose an AI engine for this mapping. Each mapping needs an engine. The associated engine will be used to extract the AI data as per the rules specified in this mapping.
- Metadata Rule: specify metadata key-value pairs to be matched for selecting a file. Multiple metadata property value pairs can be specified in this field, separated by commas only (no spaces). Only those assets that have these values for the specified properties will be sent for AI analysis.
Values can be specified like these examples:
- IPTC_City=Milan (Only assets with city value Milan will be selected for this engine).
- IPTC_COUNTRY=Italy,AND,IPTC_Season=2019 (Assets with the country Italy and Season value 2019 will be selected for this engine)Multiple metadata values should be separated by commas. AND/OR operators are also supported.Value comparison for metadata properties is case insensitive, which means Zoom Server will match Japan with japan.When nothing is specified for this field, all assets are selected.
- Paths: specify the path to match assets from. Only files present in this path are selected for AI analysis.
- Run Once Per Asset: if this is enabled then an asset is analyzed with AI only once throughout its lifetime, even after it is moved, renamed, or a new revision is checked in. Rule name and Engine cannot be empty. Any other field left blank will match everything. For example, leaving Paths blank will match all paths on the Zoom Server.
- Click Save to save the mapping rule.
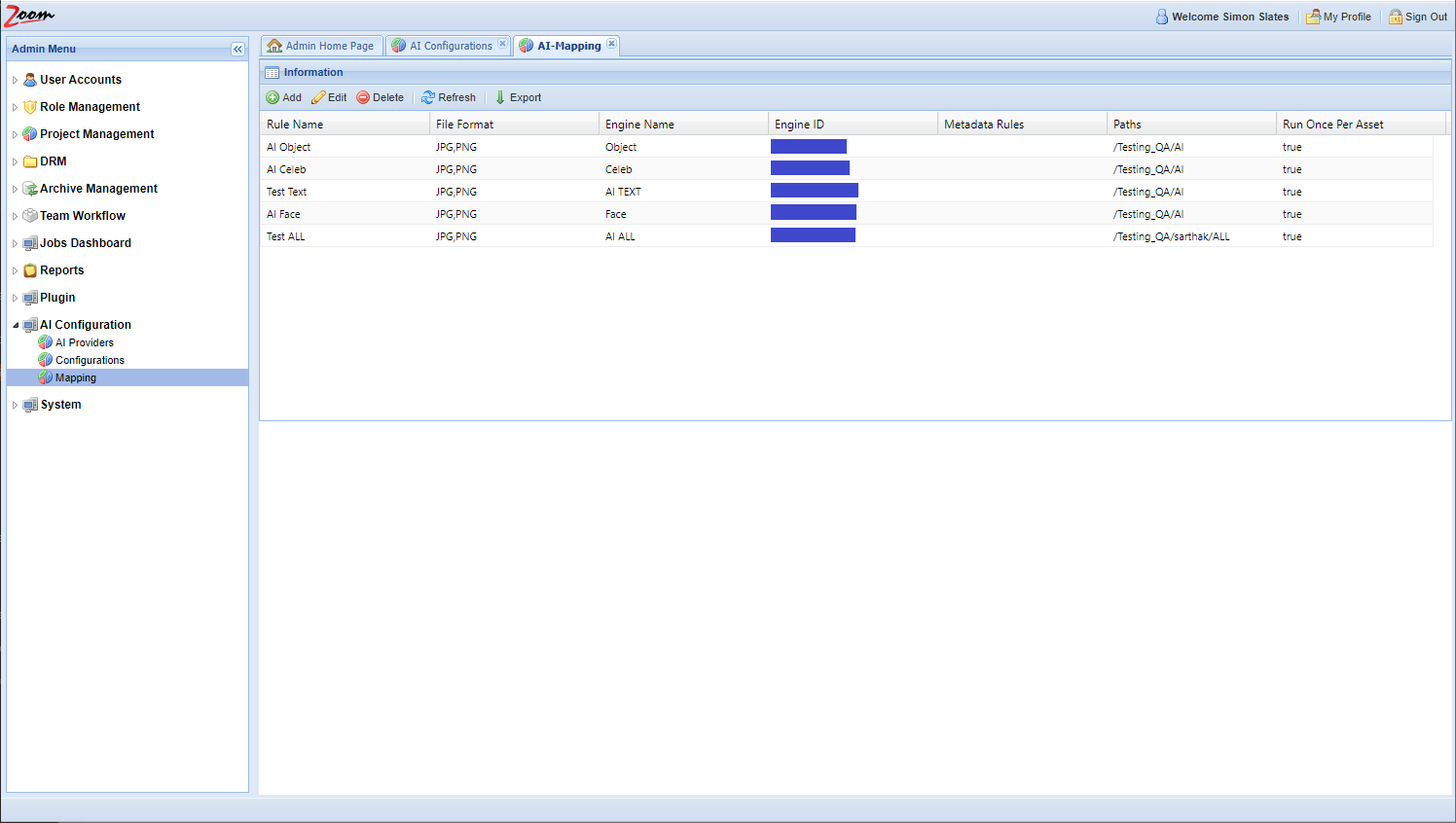
Veritone’s AI configuration in Zoom is now complete.
AI Types supported in Zoom
Zoom supports a fixed number of AI types. AI type is the way data is matched by the AI engine. These AI types are provided by your AI provider. These are later configured in Zoom as shown in the AI Configurations section above. The following AI types are supported in Zoom:
- face – denotes and categorizes AI data related to human faces. This data has various information related to faces, such as age, emotions, race, etc.
- object – identifies and names objects and items in the real world, like glasses, bicycles, crayons, ties, suits, etc.
- text – denotes extracted text (like OCR) from images or videos.
- celeb – denotes well-known celebrities and is attached to their name.
- transcription – this is used when speech (audio) is transcribed from an audio or video file.
You should check with your AI provider about the AI types provided with their AI engines.
Configure Amazon AI in Zoom
To finish configuring Amazon AI Provider, you also need to set it up on your Zoom Server.
After setting up the Hub Server and configuring Amazon settings on it, we also need to configure detailed Amazon AI parameters in Zoom using the Web Management Console. We need to set Amazon as the AI Provider, provide configurations for AI engines, and then map AI rules to AI engines. Follow these steps:
AI Providers
You need to add one or more AI providers to work with Zoom. Follow these steps to add a provider:
- Log in to the Web Management Console and click AI Providers under the AI Configuration node in the Admin Menu sidebar. You need to add an AI Provider here.

- Inside the AI Providers panel, click Add and choose Amazon from the list of AI Providers.
- Select the newly added row for Amazon. Its details will be loaded in the right side Information panel.
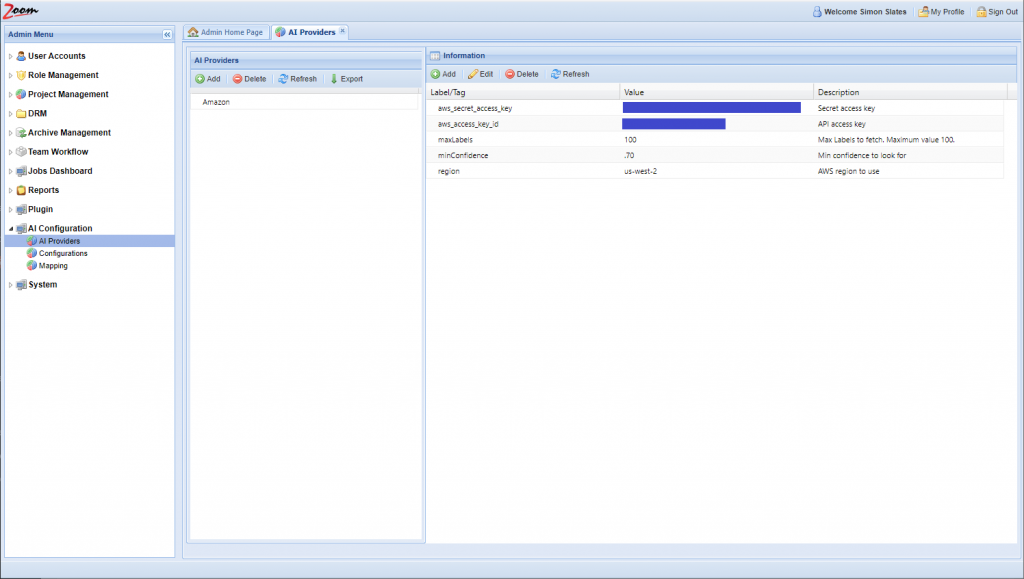
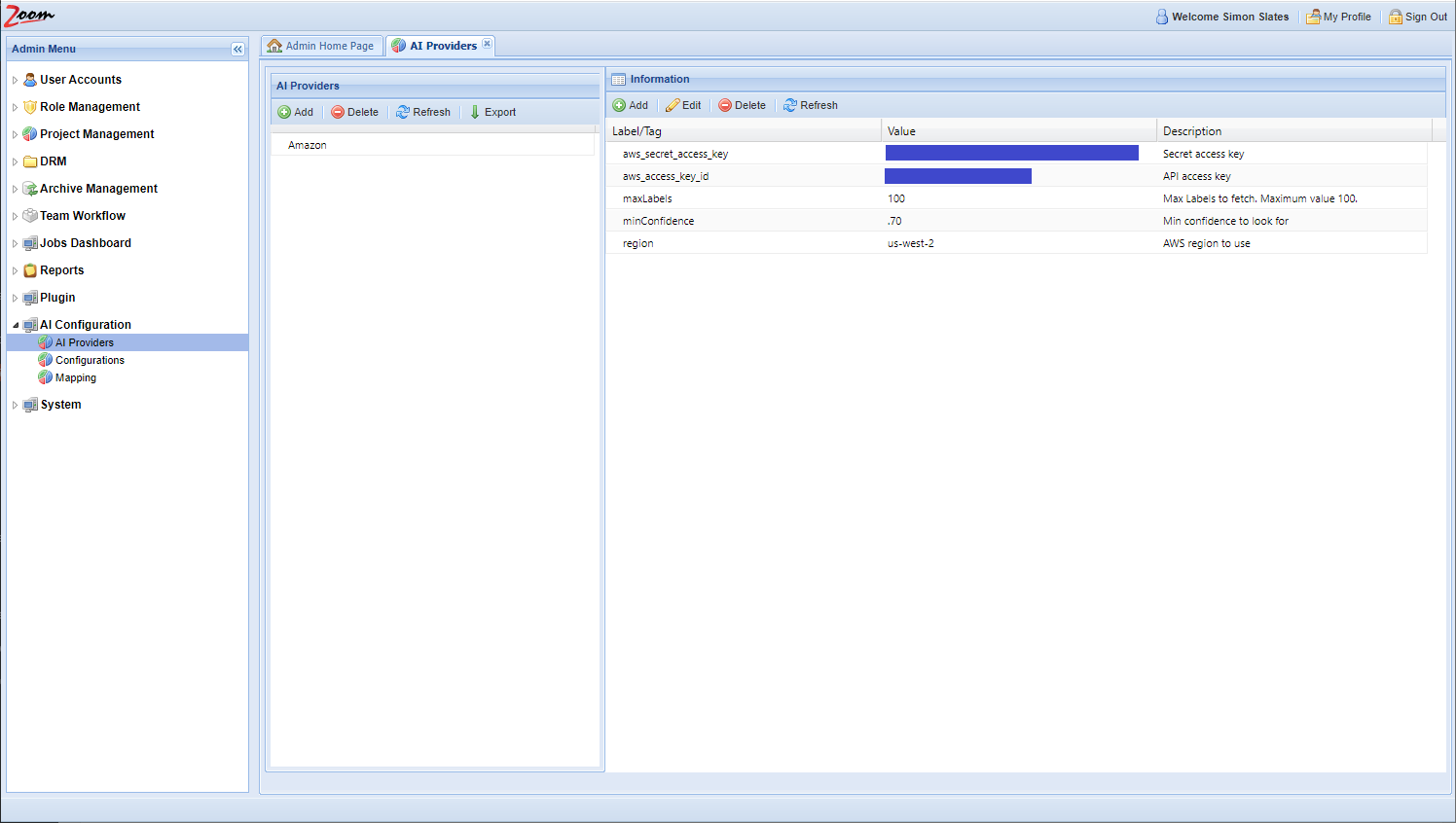
- Add/update these values in the Information Panel:
- aws_secret_access_key – specify your AWS secret access key. It is generated from amazon/aws console.
- aws_access_key_id – specify your AWS access key id. It is also generated from amazon/aws console.
- region – specify the region where this AI Provider will run the AI jobs. The default value is us-west-2.
- minConfidence – specify the minimum confidence needed for any match to be returned to Zoom as the result for an AI category. You can specify a value between 0.00 to 1.00. The default value is 0.55, which shows 55% probability.
- maxLabels – enter the maximum number of results that you want to receive for an AI category. The default value is 100, which is also the maximum number of results that Amazon can send per AI category. You can specify a value of 100 or less.
- enable – this is true by default to enable this provider. Setting this value to false will disable this provider in Zoom, so it will not be used further. If this value is missing in the configuration files, it will still be treated as true. The values specified here are all case-sensitive.For other providers, different sets of values may be needed.
- After updating the provider values, move to configure this provider on the AI Configurations page in the next section.
AI Configurations
You need to add one configuration per AI Engine provided by your AI Provider. You would get the Engine ID and type from them for each AI engine. Follow these steps to add the necessary configurations:
- In the Web Management Console, click Configurations under the AI Configuration node in the Admin Menu sidebar. You need to add AI configurations here for your AI Provider.
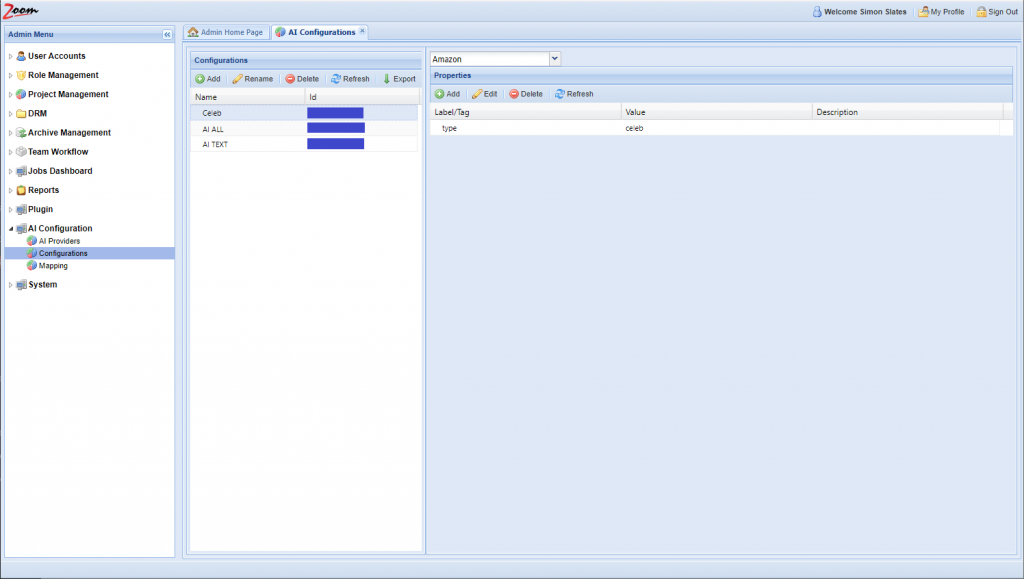
- Inside the Configurations panel, click Add to add a new configuration.

- Provide a name for the new configuration. It is best to use names relating to the task performed by the engine and the names should be unique.
- Select the newly added row for the new configuration. Its details will be loaded in the right side Properties panel.
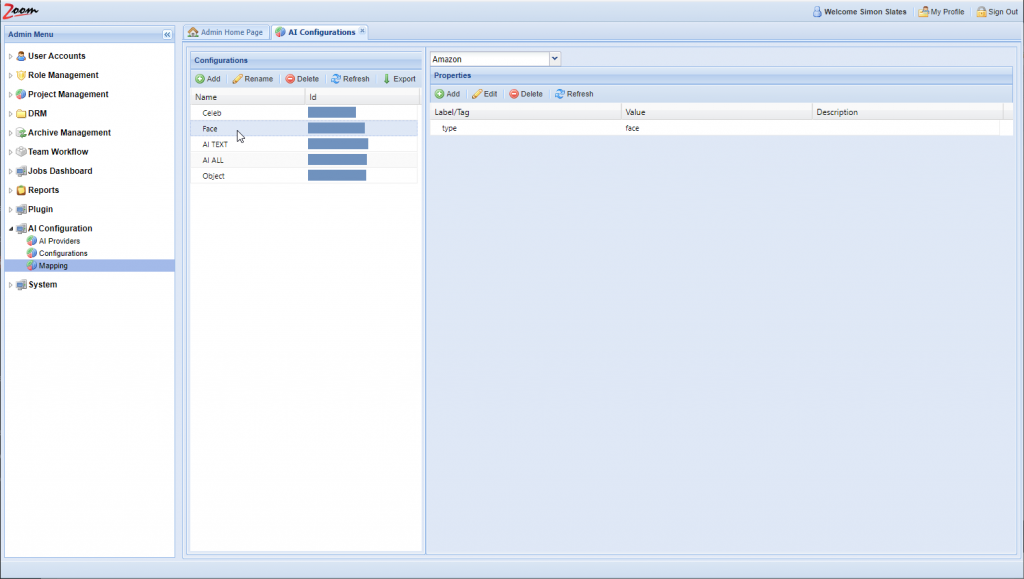
- Choose an AI provider from the AI Providers dropdown box above the Properties panel. Choose the provider, Amazon, that we had added in the previous section.
- Click Add in the Properties panel for each property that you want to add for the new AI Configuration.
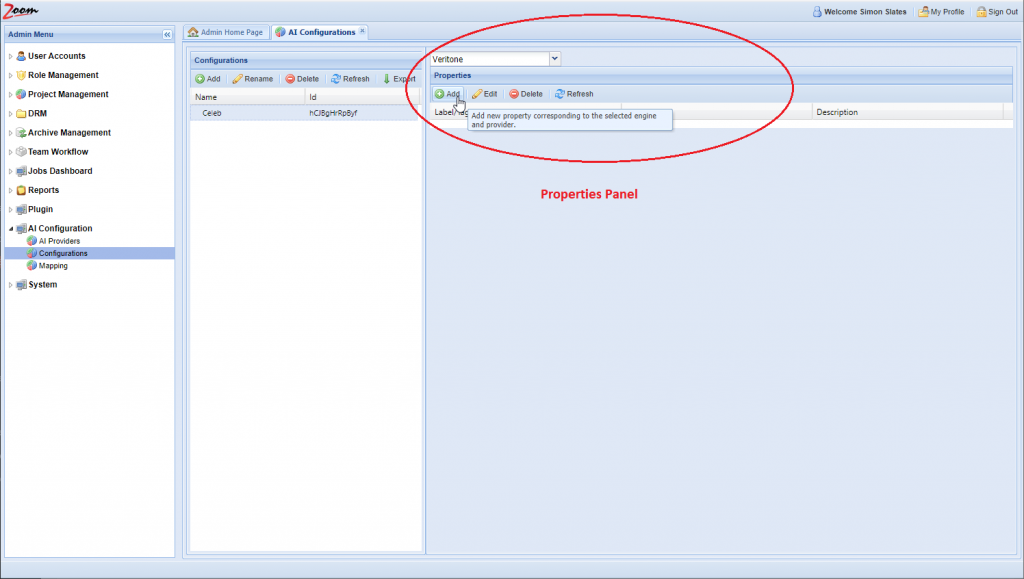
- You need to fill Label and Value for each property at the minimum. The Description is optional.
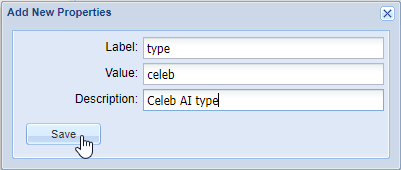 For example, for the AI Type property, you should add the Label as type and Value as its AI type. So, Label will be type and Value may be transcription.
For example, for the AI Type property, you should add the Label as type and Value as its AI type. So, Label will be type and Value may be transcription. - Each configuration that you add should have exactly one AI Engine and one AI Type property in it. Some configurations will also need additional properties depending on the AI Engine that is being configured. Each group of AI Engine and AI Type together should be exclusively configured in one configuration only, and these cannot be repeated. Add these properties for the new configuration:
Label Value type Add the AI type that should be associated with this configuration. This is the AI Engine’s AI Type that is provided by Veritone. enable Optionally, set this property to false to disable this AI Engine. The Engine will be disabled and no further jobs will be created using this AI Engine. Similarly, setting ‘enable’ as false for an AI Provider will disable that provider and all the engines associated with it.minConfidence Specify the confidence level in the range from 0.00 to 1.00. Only data that has a confidence level equal or higher will be added to the Zoom database. The rest will be discarded. The value of minconfidence here overrides the same value from the AI Provider configuration above. The value from AI Provider configuration will be used if it is not specified here. maxLabels The default value is 100. Amazon can give a maximum of 100 values per AI category. You can set lower than 100 if fewer values are required in the result. The value of maxLabels here overrides the same value from the AI Provider configuration above. The value from AI Provider configuration will be used if it is not specified here. type should be specified for each AI Engine.enable, minConfidence, and maxLabels are optional.
All property values specified are case-sensitive. - After updating the configurations for engines inside your AI providers, move to map the engines with configurations on the AI-Mappings page in the next section.
AI-Mapping
Finally, you need to map AI engines with Zoom, to control what assets will be analyzed by each engine. Follow these steps to map asset rules to an engine:
- In the Web Management Console, click Mapping under the AI Configuration node in the Admin Menu sidebar.
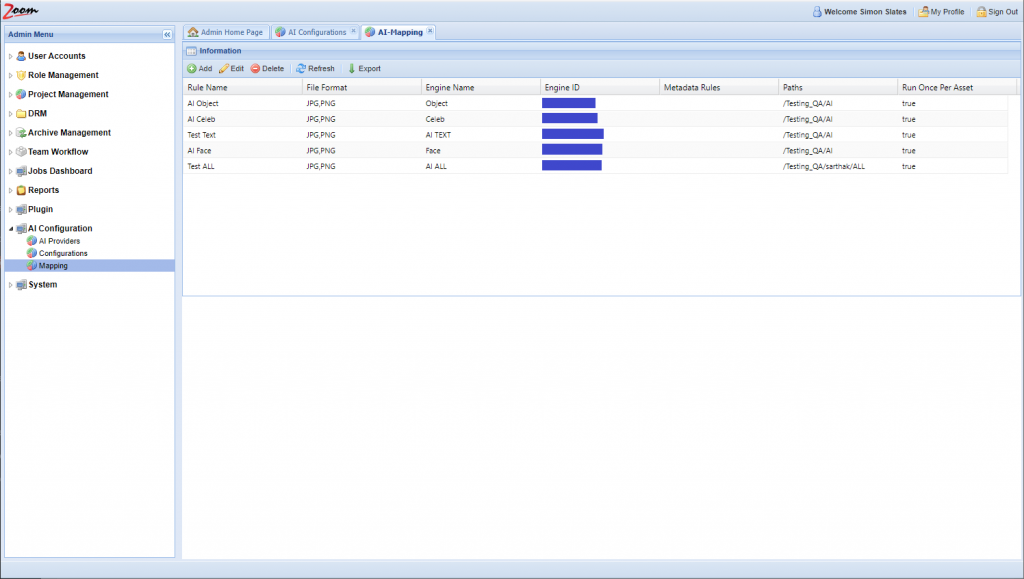
- Click Add to add a new mapping rule.
- Specify these values:
- Rule Name: specify a name for the mapping -rule.
- File Format: specify a comma-separated list of file extensions associated with this mapping. For e.g.: MP4, MXF. Only files matching the given extension(s) will be sent for analysis to the AI Engine. If not specified, then all file types are considered valid for this mapping.
- Engine: choose an AI engine for this mapping. Each mapping needs an engine. The associated engine will be used to extract the AI data as per the rules specified in this mapping.
- Metadata Rule: specify metadata key-value pairs to be matched for selecting a file. Multiple metadata property value pairs can be specified in this field, separated by commas only (no spaces). Only those assets that have these values for the specified properties will be sent for AI analysis.
Values can be specified like these examples:
- IPTC_City=Milan (Only assets with city value Milan will be selected for this engine).
- IPTC_COUNTRY=Italy,AND,IPTC_Season=2019 (Assets with the country Italy and Season value 2019 will be selected for this engine)Multiple metadata values should be separated by commas. AND/OR operators are also supported.Value comparison for metadata properties is case insensitive, which means Zoom Server will match Japan with japan.When nothing is specified for this field, all assets are selected.
- Paths: specify the path to match assets from. Only files present in this path are selected for AI analysis.
- Run Once Per Asset: if this is enabled then an asset is analyzed with AI only once throughout its lifetime, even after it is moved, renamed, or a new revision is checked in. Rule name and Engine cannot be empty. Any other field left blank will match everything. For example, leaving Paths blank will match all paths on the Zoom Server.
- Click Save to save the mapping rule.
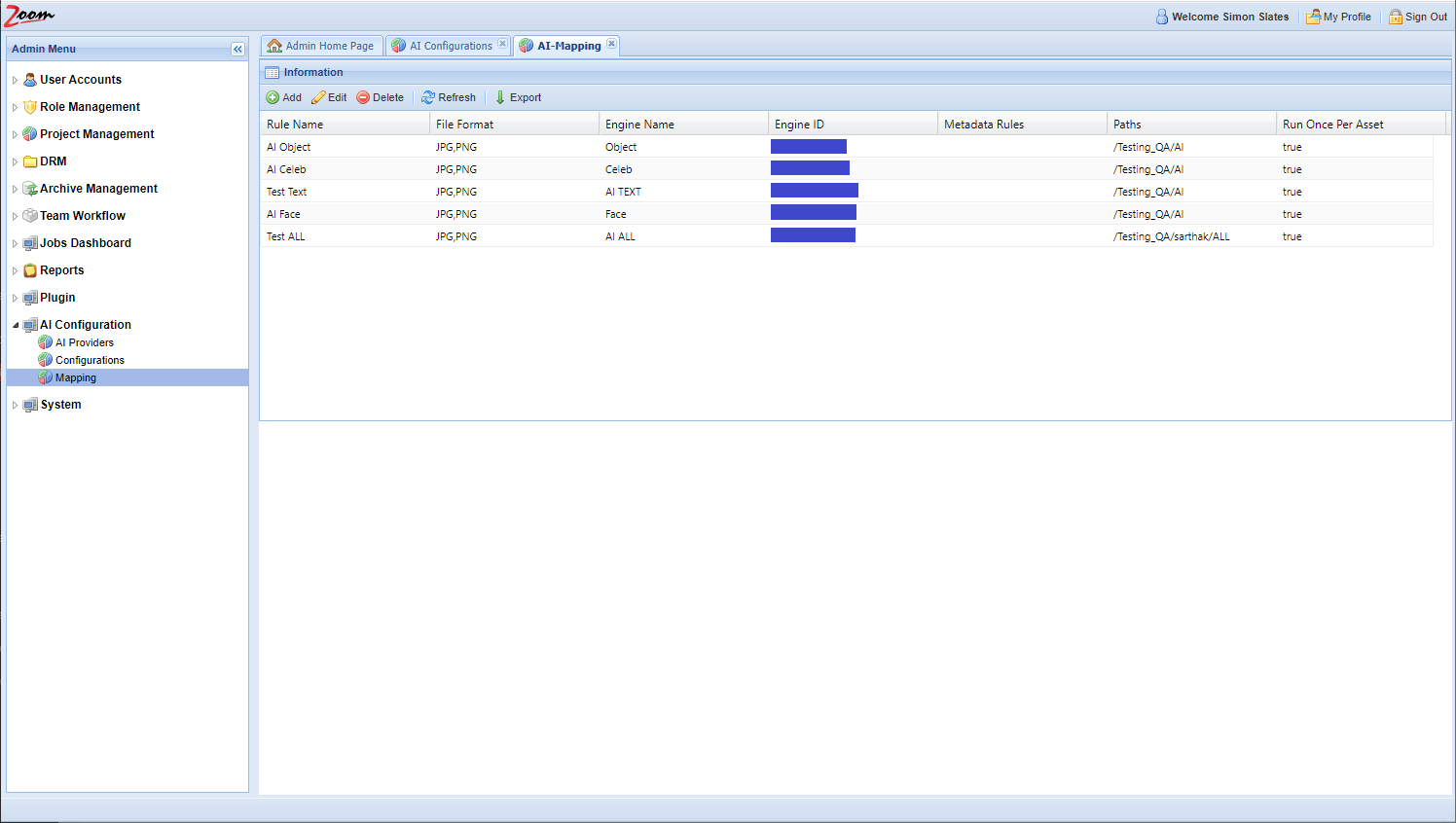
Amazon’s AI configuration in Zoom is now complete.
AI Types supported in Zoom
Zoom supports a fixed number of AI types. AI type is the way data is matched by the AI engine. These AI types are provided by your AI provider. These are later configured in Zoom as shown in the AI Configurations section above. The following AI types are supported in Zoom:
- face – denotes and categorizes AI data related to human faces. This data has various information related to faces, such as age, emotions, race, etc.
- object – identifies and names objects and items in the real world, like glasses, bicycles, crayons, ties, suits, etc.
- text – denotes extracted text (like OCR) from images or videos.
- celeb – denotes well-known celebrities and is attached to their name.
- all – this is used to fetch all types of AI data from Amazon. It is generally not recommended.
The AI type transcription is not supported by Amazon.
You should check with your AI provider about the AI types provided with their AI engines.
Validate Your AI Setup
After installing and configuring Hub, as soon as you are finished setting up your AI provider, configuration, and mappings in Zoom, your AI module in Zoom starts locating existing assets in the Zoom repository to be eligible for AI analysis. If any existing or new assets match your configured AI mapping rules, these are sent over to your AI Provider. In the case of Veritone AI provider, these are sent to a shared A3 bucket. The process is managed by the Hub Server and the progress of an AI job can be viewed on the Hub Dashboard.
When the process finishes and AI data is returned by your AI provider, it is saved into Zoom and can be viewed along with other metadata for the analyzed assets inside WebClient. The flow is shown below.
AI analyzed asset in Web Client
For a video
The most common forms of analysis used on videos include transcription (speech to text), object detection, logo detection, and celebrity detection. Zoom displays the AI-generated tags as data timelines in the Web Client’s data timeline view. Each AI engine creates its own data timeline.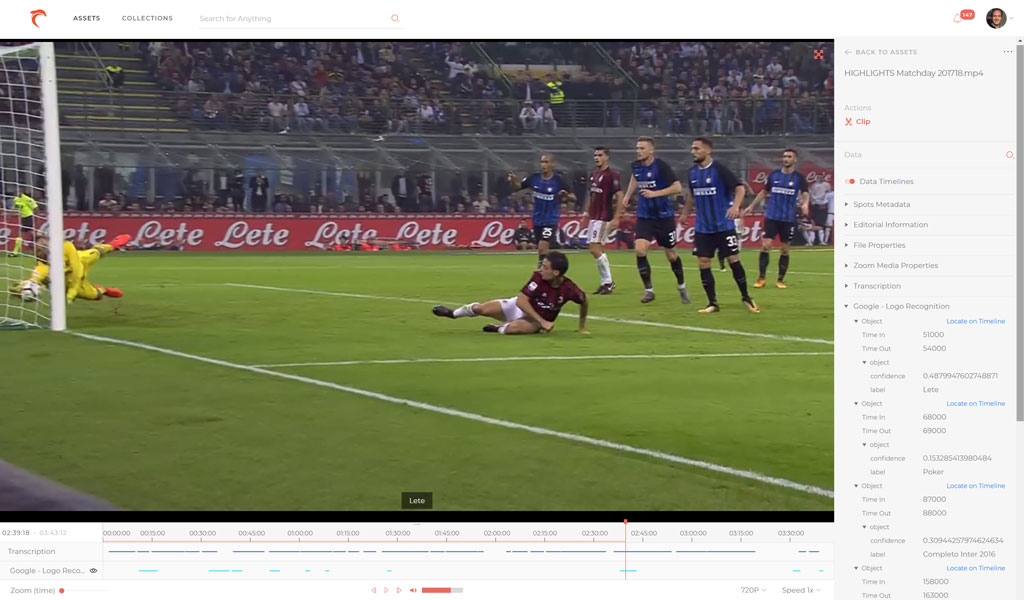
 icon next to each layer in the timeline.
Additionally, expanding the metadata in the right panel will display Locate links that you can click to be brought to that frame in the video.
icon next to each layer in the timeline.
Additionally, expanding the metadata in the right panel will display Locate links that you can click to be brought to that frame in the video.
For an image
Text (OCR) and object recognition are most commonly employed for images as shown in the screen below.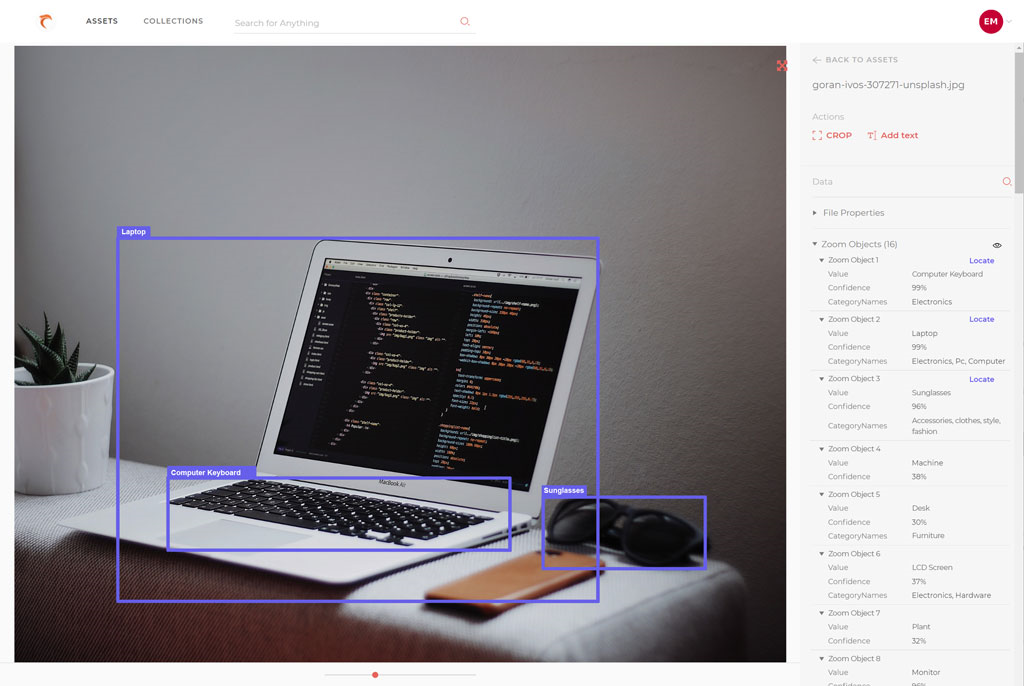
button next to the data layer name in the right-side panel. If locator boxes were returned by the AI engine, they will be displayed over the image so you can see which tag corresponds to which area in the image.
You can also expand the metadata on the right panel to show Locate links for toggling the data point marked on the asset.
AI Jobs Dashboard
The AI jobs are managed by the Hub Server, so you need access to the Hub Server to view the AI Jobs Dashboard.
Access the AI Jobs Dashboard using the Hub Server IP at http://[HubIP]:8282/
The AI Dashboard is shown.
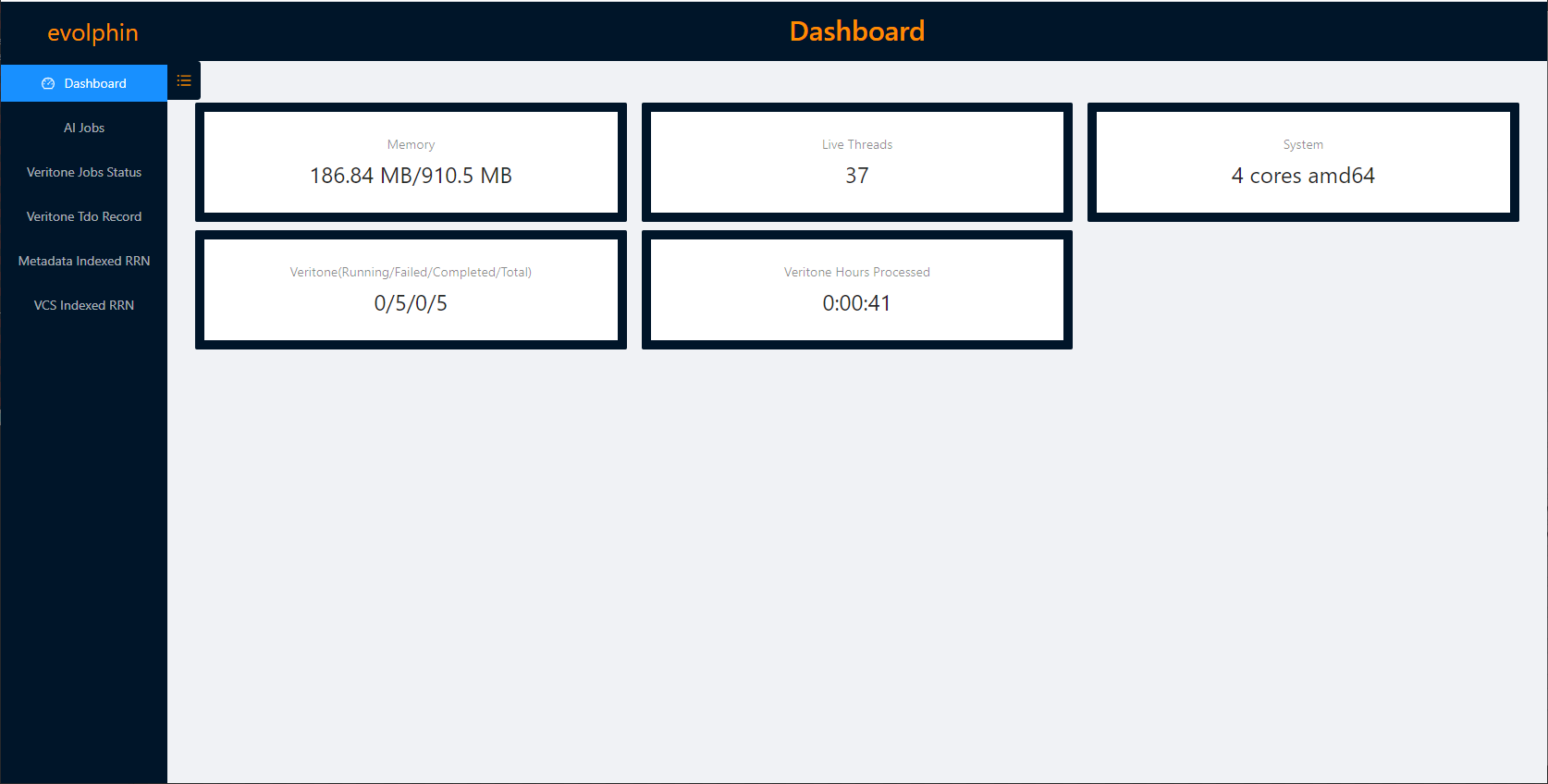
It shows system information about the AI processes in Zoom. Click AI Jobs to see the jobs on the server.
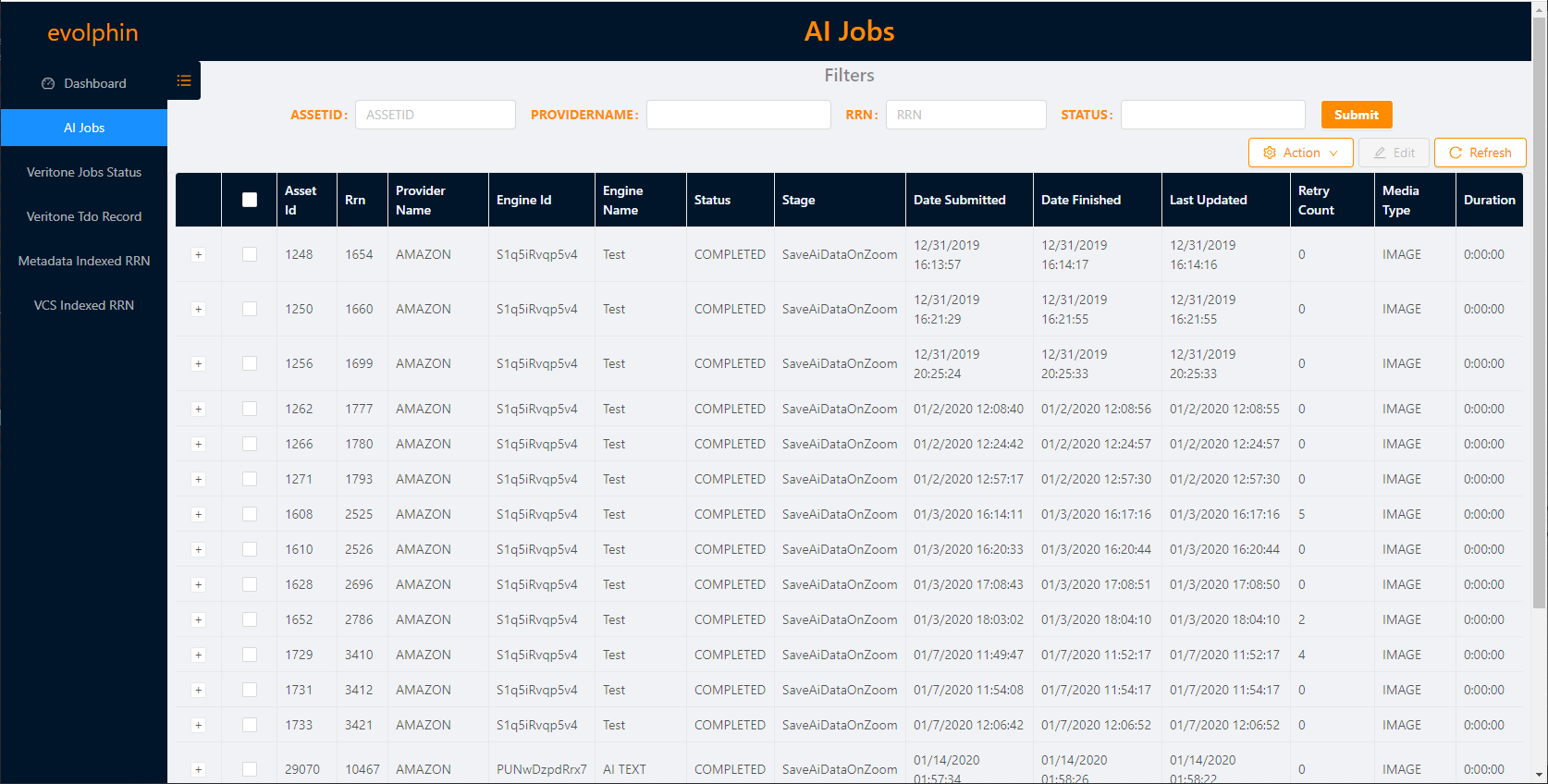
The jobs are listed in reverse chronological order, with the latest jobs showing on top. If there are multiple pages then you can scroll using the Page number links on the bottom right or the Previous Page and Next Page buttons. You can also jump 5 pages in front or back by clicking the Previous 5 Pages or Next 5 Pages buttons that appear in place of the … shown for multiple pages.
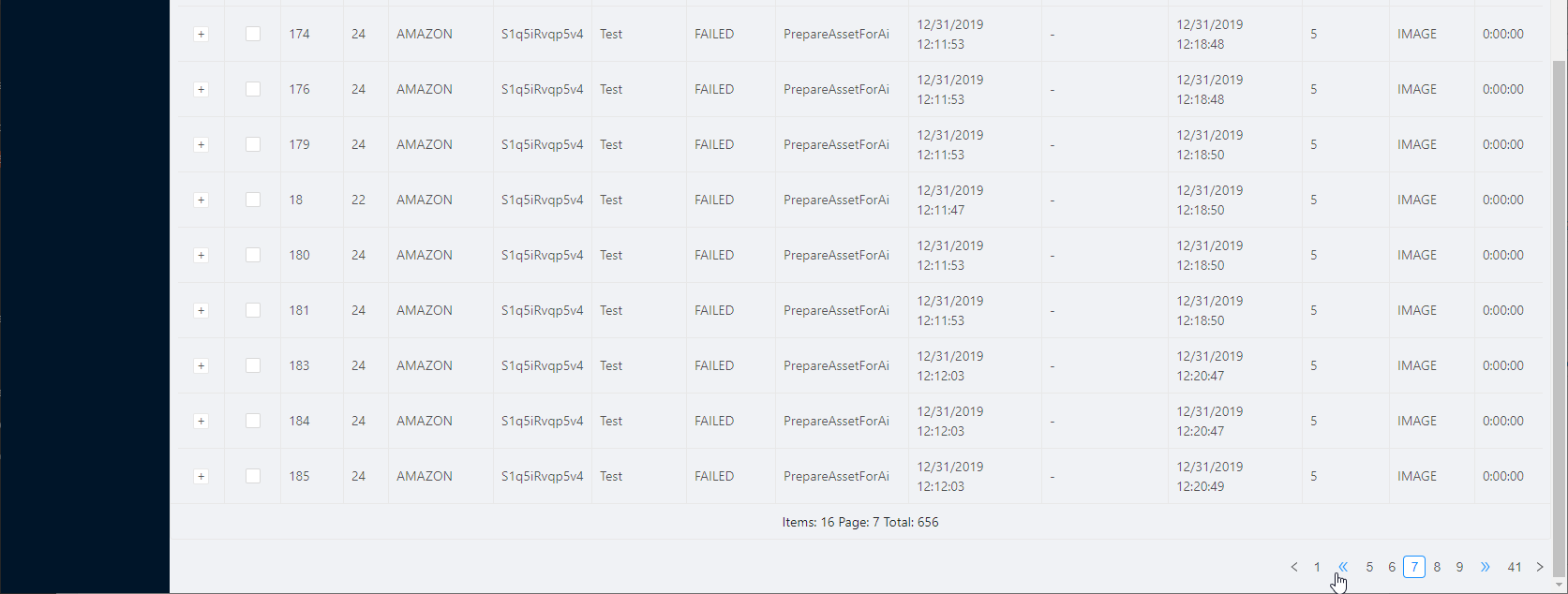
You can filter jobs based on a few criteria listed on the top. Specify one or more of the filters and click Submit to apply the filters on the jobs listed below.
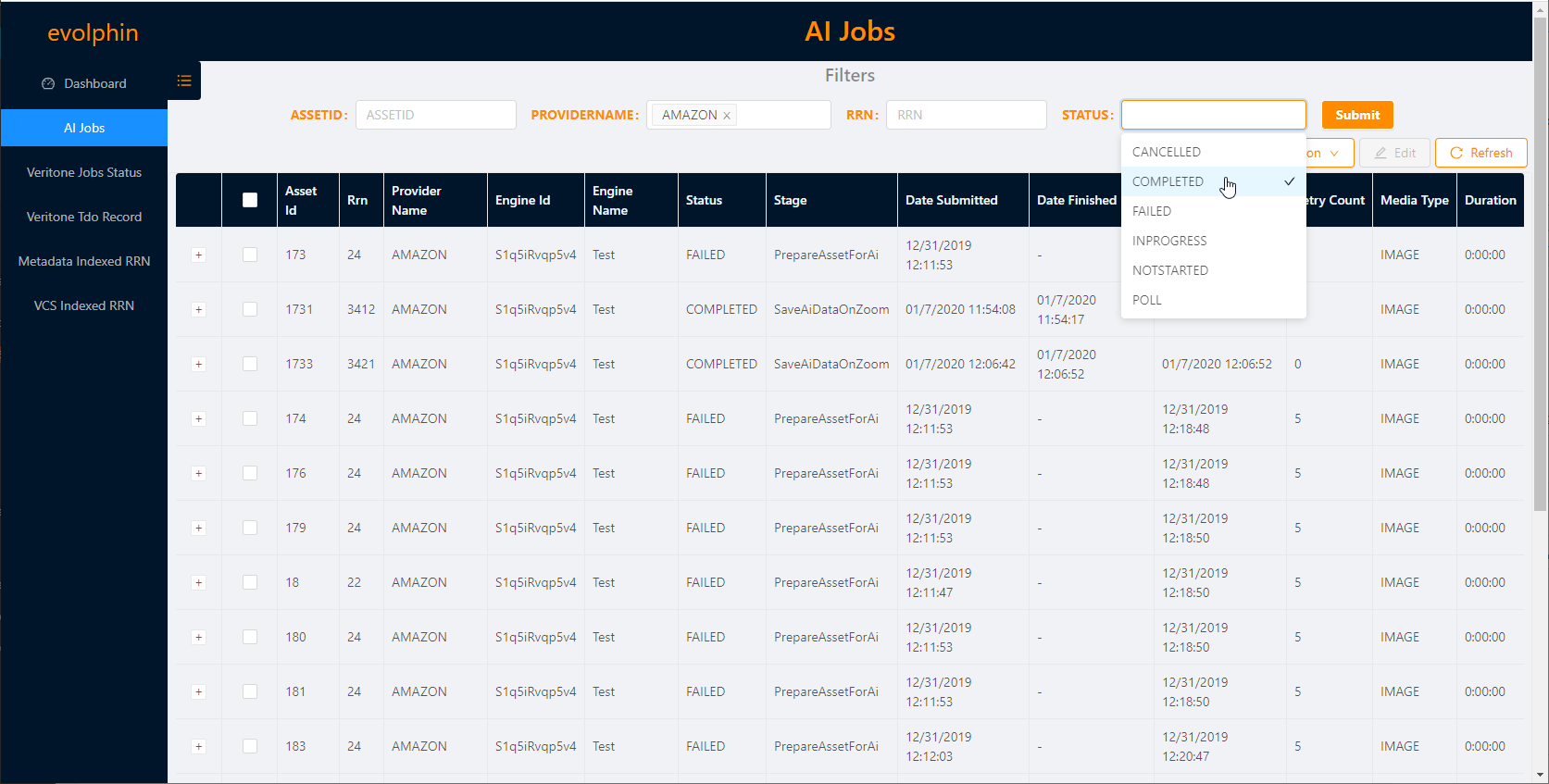
You have the option to select one or more jobs, by selecting the checkbox in front of their row. Select one or more jobs and click Edit to edit the details saved with the job. You can also select one or more jobs and select an Action from the Action dropdown in the top right.
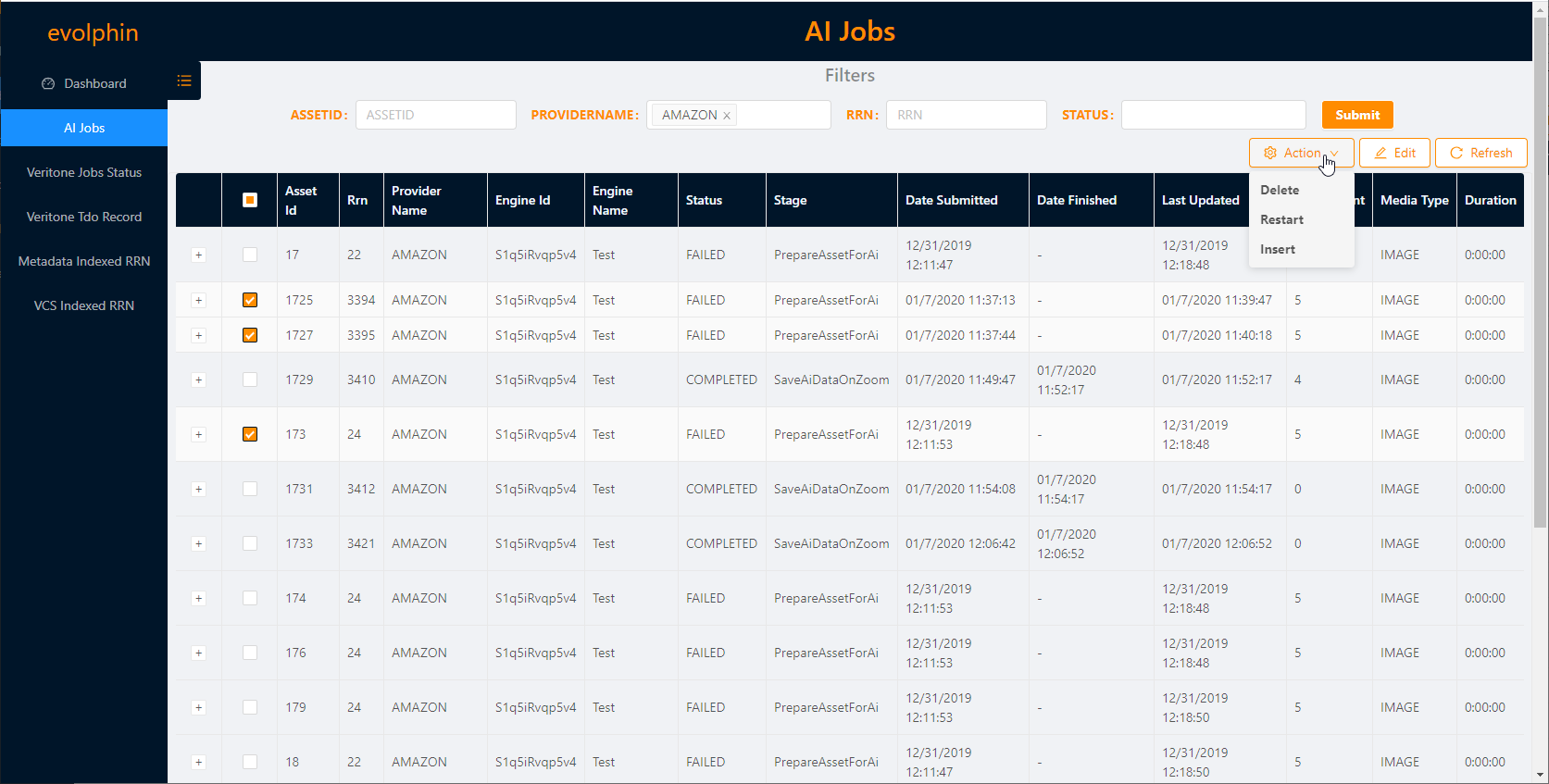
Select Delete to delete that job. Any job that has started to execute on the external AI Provider will continue to be worked on.
Select Restart to start a failed job.
Select Insert to insert a new job record.
Click the + before a job row to view more details about the job.
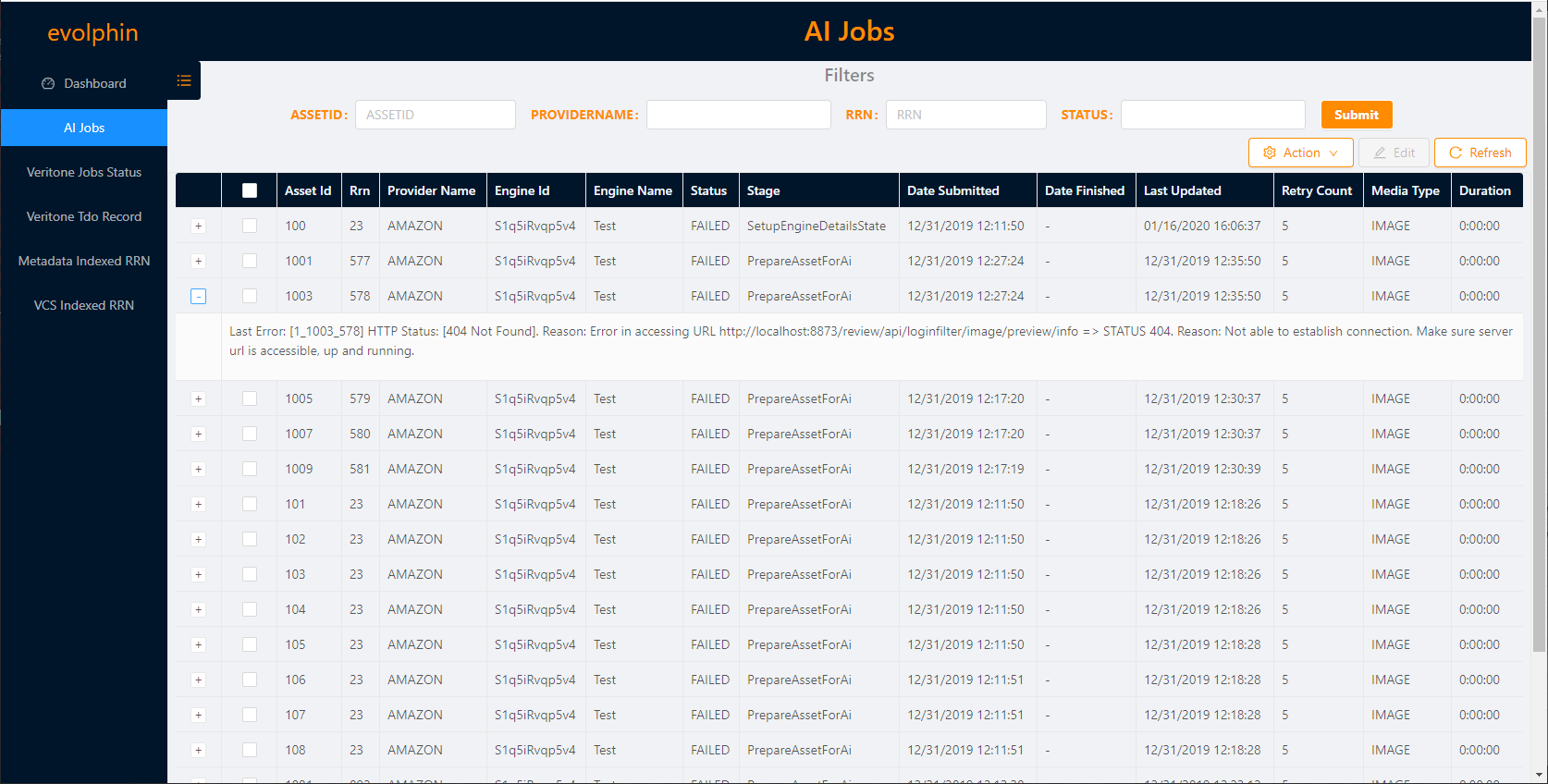
The details depend on the status of the job. For completed jobs, it shows the assets affected.
For failed jobs, it shows the reason for failure.
Click Refresh to reload the data.