Once you have configured Hub in Zoom and installed your Hub Server, you can add Veritone settings to it.
Start the Hub Server where you want to run AI jobs. On this Hub Server, open the conf folder inside the Hub installation directory. Inside the conf folder, locate ai-spec.xml.
ai-spec.xml will be created automatically on the Hub Server after it is started for the first time.
<AiSpec xmlSpecVersion=”4″>
<ScratchDirSpec>
<scratchDir>/home/evolphin/.ejh/tmp/ai</scratchDir>
</ScratchDirSpec>
<ExecutorSpec>
<maxThreadCount>4</maxThreadCount>
<maxRetryCount>5</maxRetryCount>
<TimeoutSpec>
<timeout>60</timeout>
<timeUnit>SECONDS</timeUnit>
</TimeoutSpec>
<queueSize>100</queueSize>
</ExecutorSpec>
<previewServerUrl>http://localhost:8873</previewServerUrl>
<PreviewFetchHttpCallTimeout>
<timeout>60</timeout>
<timeUnit>SECONDS</timeUnit>
</PreviewFetchHttpCallTimeout>
<RekognitionSpec>
<defaultMaxLabel>100</defaultMaxLabel>
<defaultMinConfidence>0.5</defaultMinConfidence>
<awsDefaultRegion>us-west-2</awsDefaultRegion>
</RekognitionSpec>
<batchSize>100</batchSize>
<VeritoneSpec>
<queriesDirectory>veritone-queries</queriesDirectory>
<awsAccessKeyId>XYZ</awsAccessKeyId>
<secretAccessKey>ABCDEF</secretAccessKey>
<bucketName>buckername</bucketName>
<region>bucker-region</region>
<defaultPublicLinkExpiryInDays>7</defaultPublicLinkExpiryInDays>
<defaultMinConfidence>0.0</defaultMinConfidence>
<minimumValueLength>0</minimumValueLength>
<maximumVeritoneJobs>2</maximumVeritoneJobs>
</VeritoneSpec>
<AiJobCountLimits>
<amazonAiProviderLimit>0</amazonAiProviderLimit>
<veritoneAiProviderLimit>10</veritoneAiProviderLimit>
</AiJobCountLimits>
<rrnToStartPollingFrom>0</rrnToStartPollingFrom>
</AiSpec>
<ScratchDirSpec>
<scratchDir>/home/evolphin/.ejh/tmp/ai</scratchDir>
</ScratchDirSpec>
<ExecutorSpec>
<maxThreadCount>4</maxThreadCount>
<maxRetryCount>5</maxRetryCount>
<TimeoutSpec>
<timeout>60</timeout>
<timeUnit>SECONDS</timeUnit>
</TimeoutSpec>
<queueSize>100</queueSize>
</ExecutorSpec>
<previewServerUrl>http://localhost:8873</previewServerUrl>
<PreviewFetchHttpCallTimeout>
<timeout>60</timeout>
<timeUnit>SECONDS</timeUnit>
</PreviewFetchHttpCallTimeout>
<RekognitionSpec>
<defaultMaxLabel>100</defaultMaxLabel>
<defaultMinConfidence>0.5</defaultMinConfidence>
<awsDefaultRegion>us-west-2</awsDefaultRegion>
</RekognitionSpec>
<batchSize>100</batchSize>
<VeritoneSpec>
<queriesDirectory>veritone-queries</queriesDirectory>
<awsAccessKeyId>XYZ</awsAccessKeyId>
<secretAccessKey>ABCDEF</secretAccessKey>
<bucketName>buckername</bucketName>
<region>bucker-region</region>
<defaultPublicLinkExpiryInDays>7</defaultPublicLinkExpiryInDays>
<defaultMinConfidence>0.0</defaultMinConfidence>
<minimumValueLength>0</minimumValueLength>
<maximumVeritoneJobs>2</maximumVeritoneJobs>
</VeritoneSpec>
<AiJobCountLimits>
<amazonAiProviderLimit>0</amazonAiProviderLimit>
<veritoneAiProviderLimit>10</veritoneAiProviderLimit>
</AiJobCountLimits>
<rrnToStartPollingFrom>0</rrnToStartPollingFrom>
</AiSpec>
You need to set a few tags here:
- scratchDir – set this for a temporary directory which is used to hold data in an intermediate state. For example, file proxies are kept in this directory until they are sent for AI analysis. Another use of it is to store AI data in the intermediate state. It is recommended to point this directory to a large storage volume where hundreds of proxy files can be stored easily. These files will be removed after completion of a job, but enough space should be provisioned for the intermediate time.
- maxThreadCount – set this for the maximum number of AI jobs that can be executed in parallel.
- maxRetryCount- set this for the maximum number of times a job should be retried on failure before marking it as failed.
- previewServerUrl – this tag should point to your Preview Server’s URL. Without populating this tag, the Hub will not be able to download the proxies for AI analysis.
- bucketName inside veritoneSpec – you need to specify the name of the S3 bucket for storing proxies for AI analysis. The hub needs a temporary staging S3 bucket to upload and store proxies. This is only required when Veritone is used as an AI connector.
- awsAccessKeyId inside veritoneSpec – specify the Access Key ID for the S3 bucket specified above.
- secretAccessKey inside veritoneSpec – specify the Secret Access Key for accessing the S3 bucket.
- region – set the AWS region where the S3 bucket is hosted.
- defaultPublicLinkExpiryInDays – set this as the number of days after which data will auto clean from the S3 bucket. This is the same as the number of days configured for the expiration rule on this bucket inside lifecycle rules. It is recommended to set it to 7 days.
- maximumVeritoneJobs – controls the maximum number of Veritone AI jobs to run at one time. If these many jobs are running on Veritone, no further jobs will be scheduled.
- veritoneAiProviderLimit – set this property to limit the total number of jobs that the Hub will send to Veritone AI for processing. The Hub will stop processing more files after reaching this limit. This is used to prevent going over the allotted number of jobs for billing purposes.
Optional advanced settings:
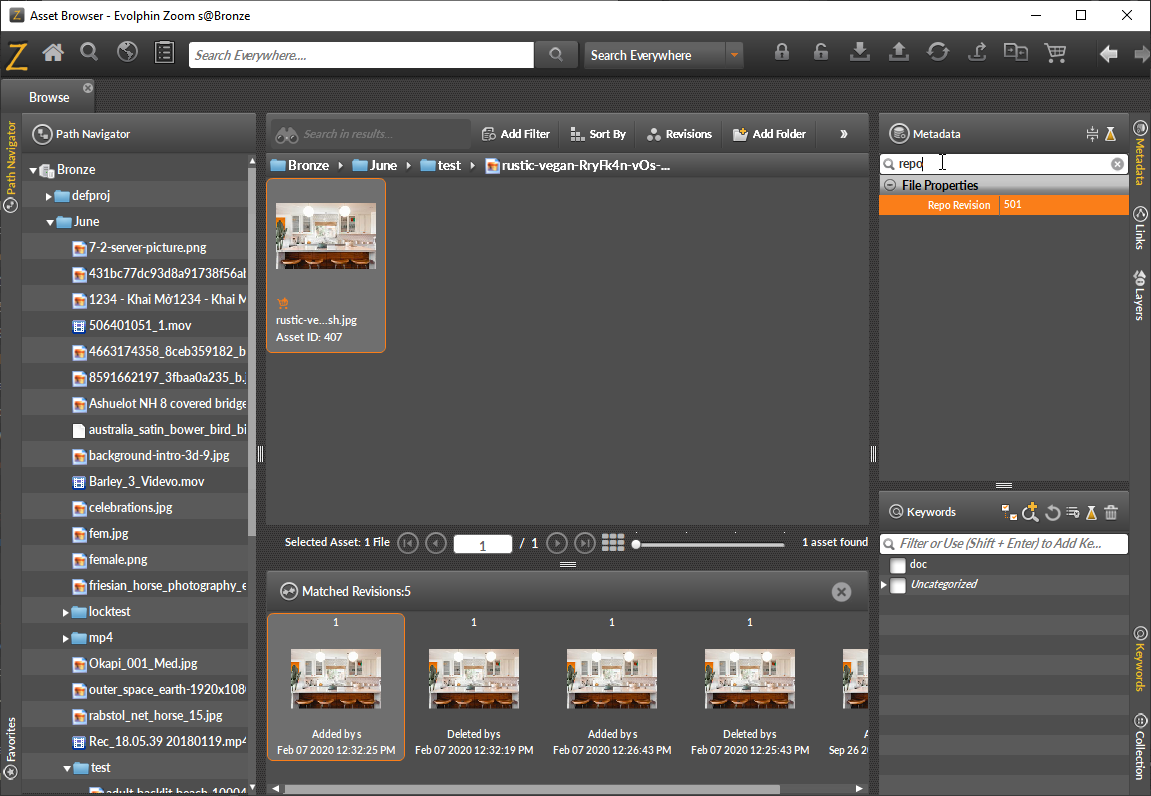
- rrnToStartPollingFrom – set this value to the RRN from where the system should start scanning from. When this value is 0 or not set, new asset scanning starts from the first RRN. This change is only needed if you do not want to scan the whole repository with AI but only assets added on and after a specific RRN. RRN is the Repository Revision Number, the transaction number that is generated for each change to the Zoom repository. There would be one or more assets added, updated, or deleted together for a single RRN. You can fetch the RRN by searching for Repo Revision metadata property under File Properties for the asset in the Asset Browser.
Save and close the file.
Restart your Hub by running Hub restart from the bin folder inside Hub’s installation directory.